Cleaning up the Snorby Database
I had an old snorby install get stale with a lot of data since the cache_job wasn’t running. I ran into a lot of cool sites which helped me clean up the database.
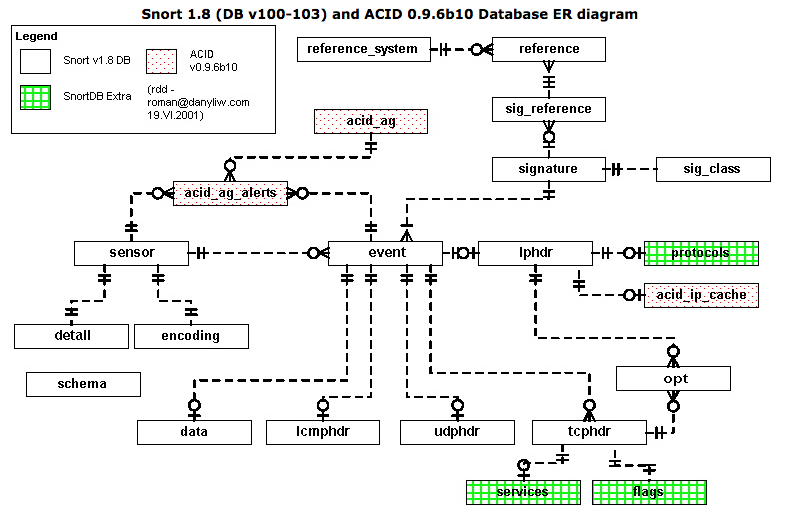
Snorby Database
I didn’t find a good diagram of the database schema for snorby specifically but I did find a close one from snort. From ACID: Database (v100-103) ER Diagram:
Another good site Querying SNORT SQL database has good examples of queries to show you the contents of the database. Some useful queries from that site:
select count(*) from event where timestamp between '2012-07-10' and '2012-07-11';
select count(*) from event where date(timestamp)=date(now());
select count(*),date(timestamp) as count from event group by date(timestamp);
select sig_id,sig_name from signature;
select sig_id,left(sig_name,30),count(*) from signature as s, event as e where s.sig_id=e.signature group by sig_name;
select sig_id,left(sig_name,30),count(*) from signature as s, event as e where s.sig_id=e.signature and date(e.timestamp)=date(now()) group by sig_name;
select signature,count(*) as cnt,inet_ntoa(ip_src) from event,iphdr where event.cid=iphdr.cid and event.sid=iphdr.sid group by ip_src order by cnt;
select inet_ntoa(iphdr.ip_src) as SRC,inet_ntoa(iphdr.ip_dst) as DST,timestamp from event,iphdr,icmphdr where (icmphdr.sid,icmphdr.cid)=(event.sid,event.cid) and (iphdr.sid,iphdr.cid)=(event.sid,event.cid) and icmp_type=8 limit 3;
select signature.sig_name,count(*) from signature,event,iphdr where (event.cid,event.sid)=(iphdr.cid,iphdr.sid) and inet_ntoa(ip_src)='10.61.34.152' and event.signature=signature.sig_id group by sig_id;
Clean the DB Manually
There used to be a pretty good site that went over the process: “How to clean up unwanted Snorby events by Signature name” (but it seems to be offline now). I found old commands from that post here. First list the signatures that have the most counts:
SELECT e.sid, e.signature, s.sig_name, count(s.sig_name) as sig_counts FROM event e JOIN signature s ON e.signature = s.sig_id GROUP BY s.sig_name ORDER BY sig_counts DESC;
The output will look similar to this:
MariaDB [snorby]> SELECT e.sid, e.signature, s.sig_name, count(s.sig_name) as sig_counts FROM event e JOIN signature s ON e.signature = s.sig_id GROUP BY s.sig_name ORDER BY sig_counts DESC;
+-----+-----------+-----------------------------------------------------------------+------------+
| sid | signature | sig_name | sig_counts |
+-----+-----------+-----------------------------------------------------------------+------------+
| 1 | 550 | SURICATA UDPv4 invalid checksum | 5757 |
| 1 | 551 | Snort Alert [1:2260002:1] | 190 |
| 1 | 545 | SURICATA TLS error message encountered | 81 |
Using the signature names we can then clean up the events from the opt table:
DELETE so FROM opt so INNER JOIN data sd ON sd.cid = so.cid INNER
JOIN event se ON se.cid=sd.cid INNER JOIN iphdr si ON
si.cid=sd.cid INNER JOIN signature ss ON ss.sig_id = se.signature INNER
JOIN tcphdr st ON st.cid = sd.cid WHERE (ss.sig_name = "SURICATA TCPv4
invalid checksum" OR ss.sig_name = "SURICATA STREAM 3way handshake with ack in
wrong dir" OR ss.sig_name = "SURICATA STREAM 3way handshake right seq wrong
ack evasion" OR ss.sig_name = "SURICATA STREAM Packet with invalid timestamp"
OR ss.sig_name = "SURICATA UDPv4 invalid checksum") AND (so.optid = 0 OR so.optid = 1 OR so.optid = 2);
Next let’s clean up the data, event, iphdr, signature, and tcphdr tables:
DELETE FROM sd, se, si, ss, st USING data sd INNER JOIN event se INNER JOIN
iphdr si INNER JOIN signature ss INNER JOIN tcphdr st WHERE sd.cid=se.cid AND
se.signature=ss.sig_id AND se.cid=si.cid AND (ss.sig_name = "SURICATA TCPv4
invalid checksum" OR ss.sig_name = "SURICATA STREAM 3way handshake with ack in
wrong dir" OR ss.sig_name = "SURICATA STREAM 3way handshake right seq wrong
ack evasion" OR ss.sig_name = "SURICATA STREAM Packet with invalid timestamp"
OR ss.sig_name = "SURICATA UDPv4 invalid checksum" OR ss.sig_name = "SURICATA STREAM ESTABLISHED retransmission packet before last ack") AND se.cid=st.cid;
Next we can clean up any missing data from the tables:
DELETE FROM se, si, ss, st USING event se INNER JOIN iphdr si INNER JOIN
signature ss INNER JOIN tcphdr st WHERE se.signature=ss.sig_id AND
se.cid=si.cid AND (ss.sig_name = "SURICATA TCPv4 invalid checksum" OR
ss.sig_name = "SURICATA STREAM 3way handshake with ack in wrong dir" OR
ss.sig_name = "SURICATA STREAM 3way handshake right seq wrong ack evasion" OR
ss.sig_name = "SURICATA STREAM Packet with invalid timestamp" OR ss.sig_name =
"SURICATA UDPv4 invalid checksum" OR ss.sig_name = "SURICATA STREAM ESTABLISHED retransmission packet before last ack") AND se.cid=st.cid;
Clean up Old Data
I also found a couple of bugs in which the cache jobs were failing to clean up old data. Here are some data:
From the first one we can run the following to clean up the old stale data:
delete from iphdr where ip_src = 0 or ip_dst = 0;
delete from caches where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from daily_caches where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from data where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from event where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from favorites where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from notes where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from opt where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from icmphdr where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from tcphdr where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
delete from udphdr where (sid, cid) not in (select iphdr.sid as sid, iphdr.cid as cid from iphdr);
From the other one here is another good query:
DELETE FROM data USING data LEFT OUTER JOIN event USING (sid,cid) WHERE event.sid IS NULL;
DELETE FROM iphdr USING iphdr LEFT OUTER JOIN event USING (sid,cid) WHERE event.sid IS NULL;
DELETE FROM tcphdr USING tcphdr LEFT OUTER JOIN event USING (sid,cid) WHERE event.sid IS NULL;
DELETE FROM opt USING opt LEFT OUTER JOIN event USING (sid,cid) WHERE event.sid IS NULL;
Reclaiming the Space
I was using InnoDB at the time so I could run the following to get back the space:
optimize table data;
optimize table iphdr;
optimize table tcphdr;
optimize table opt;
Then we can run the cache jobs as well to rebuild/clean up the cache:
bundle exec 'rails c production'
Snorby::Jobs::SensorCacheJob.new(true).perform
Snorby::Jobs::DailyCacheJob.new(true).perform
Preventing Database Increase
I found a couple of bugs that talk manually running jobs to prune the db:
- Need to periodically remove invalid data from snorby database #183
- Delete Events #30
- Dashboard / Caching #54
But it looks like the daily_cache job has been improved to handle such corner cases and as long as you start that job on boot you should be okay. I ended up creating a script and running it on boot:
<> cat /usr/local/bin/snorby-start.sh
#!/bin/bash
cd /usr/local/snorby && /usr/bin/ruby script/delayed_job start
cd /usr/local/snorby && /usr/local/bin/bundle exec rails runner 'Snorby::Jobs::SensorCacheJob.new(false).perform; Snorby::Jobs::DailyCacheJob.new(false).perform'
exit 0
After it was said and done, I got my database to be at about 66M:
<> sudo du -sh /var/db/mysql/snorby
66M /var/db/mysql/snorby