Distributed Systems Design - Twitter
As I was checking out Distributed System Design, I kept running into a couple of success stories and one of them was Twitter. So for my own sake I wanted to just jot down what I learned from their architecture.
Existing Resources
There are a plethora of existing content on this:
- Design the Twitter timeline and search
- Designing Twitter
- Design Twitter – A System Design Interview Question
- System design for Twitter
There are also a bunch of cool YouTube Videos:
- Twitter system design, twitter Software architecture , Twitter interview questions
- System Design: How to design Twitter? Interview question at Facebook, Google, Microsoft
- Real-Time Delivery Architecture at Twitter
From those above resource there are a couple of nice diagrams of the architecture:
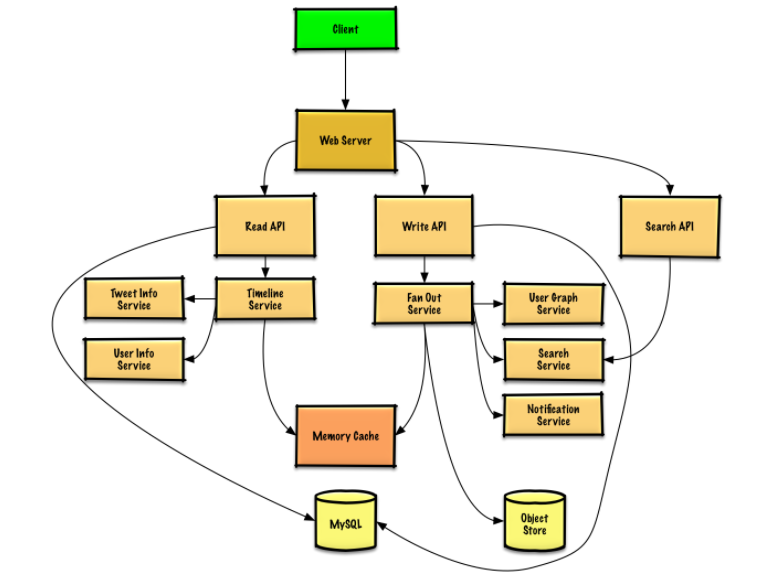

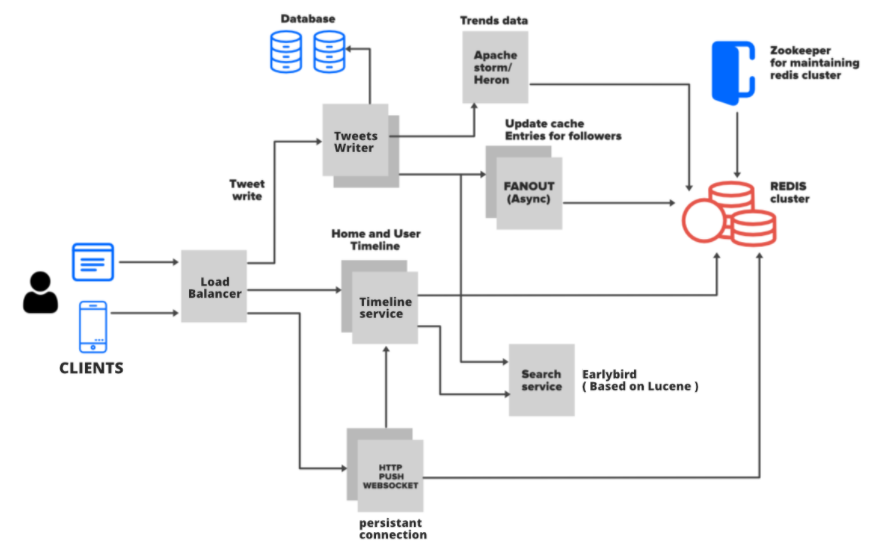
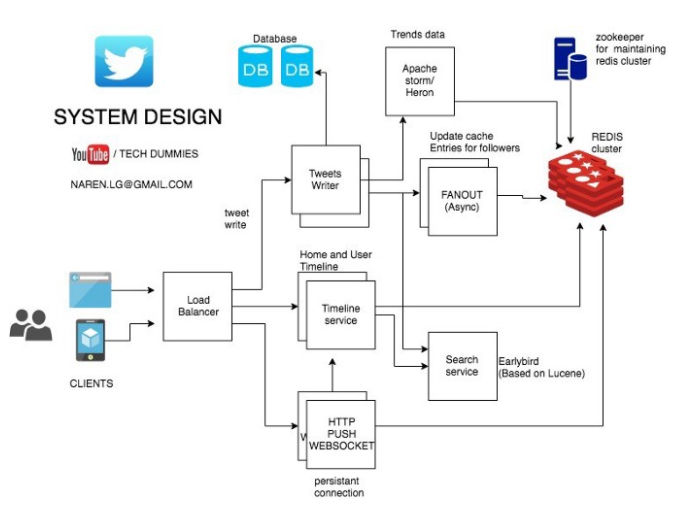
So let’s try to break it down into a couple of parts and understand how they work.
Submitting a tweet
When a write operation occurs there is a service that does a lot of the work and it’s called the fanout service. It’s basically responsible for adding your tweet to your follower’s timelines. And these home timelines are stored in redis (an in-memory database) for really fast look ups. The above links talk about why a traditional RDBMS doesn’t scale here and it’s because with twitter you would have a couple of tables (twitter, user, followers) and to create a home timeline you would need to run a pretty hefty query with joins across mulitple tables and sort by date. Since publishing tweets happens so often a traditional RDBMS would not handle this workload effectively. You will notice that they do get written to a RDBMS system in the beginning for storage but it’s not used for reads to create the timelines.
So when another user looks at their home timeline (a read request) they go to the redis cache and since the home timelines are precomputed and are stored in memory all the followers see the new tweet quickly.
Redis Clusters and Zookeeper
You will also notice that for redundancy the timelines are written to 3 different redis clusters and Zookeeper is used to manage the redis clusters. Twitter also shards the databases to spread the load across multiple instances of redis clusters.
Sharding
The main idea of sharding is to split/partition the data to be served by multiple machines so one machine is not overloaded. But how to you split the data into shards and how to route traffic to the appropriate machine which has your data. There are multiple approaches to sharding, we could shard data based on userID. As a simple example we can have store users A-C in cluster 1 and users D-F in cluster 2. We could also do it by tweet ID to combat the issue with users that make a lot of tweets.
Consistent Hashing
With the regular sharding approach we would run into some issues when scaling the cluster. To help with this we can use consistent hashing. With consistent hash sharding, data is evenly and randomly distributed across shards using a partitioning algorithm. Cassandra uses this to store data and provide redundancy. There are a couple of examples of consistent hashing but basically think of all the nodes in a cluster placed in a ring. First you hash the IP of the node and you get an angle let’s say 0-360 then you place the node on the angle of the ring. Next you hash another attribute of the data like a user id and that will generate another angle and then you put that data on the ring again. Then going clockwise you place the data on the node that is closest to angle of the data (I feel like I am doing a terrible job explaning that, so check out Consistent Hashing — An Efficient & Scalable Data Distribution Algorithm or Introducing Consistent Hashing or System Design Interview Concepts – Consistent Hashing for some awesome diagrams).
Zookeeper
So how do we tell the clients which redis machines to talk to for their data, that’s where zookeeper comes into play. From their site ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. With these features it can provide: Configuration management , Leader election, Locks in distributed systems, and Manage cluster membership. It’s like a strongly consistent key-value store. So redis machines can figure who the master is and also provide locks to make sure no data is stale (from the configuration point of view, like to tell which shard a specific node is responsible for).
Redis and Caching
Since Redis is used a cache we should about what that means. The idea of a cache is that the “most used” or the “most recently used” data is readily available via the cache. So you get the data quicker in comparison of going to the actual source. The are a couple of concepts there as well, like a Cache Hit (which is when you get the data you wanted from the cache) and there is also a Cache Miss (which is when the data you request is not in the cache and the cache system has to go to the backend to retrieve the data and store it in the cache). Usually the first request ends up in a Cache Miss, these mostly apply to reads.
Now with writes you can use different write policies:
- write-through - this is when if there is a cache miss you write to both the cache and the backend store (synchronously).
- write-back (or write-behind) - this is when the data is first written to the cache and then eventually written to the backend store when new data is about to be replace the originally written data
The “write-back” write cache policy brings up a point of when to remove data from cache (the replacement policy). The most common one is called LRU (Least Recently Used), where least recently accessed data is replaced first. With CDN (Content Delivery Network) which is network caching system there are also TLRU (Time aware Least Recently Used) where a TTL for cache is set and is removed with the TTL is expired.