Migrating To Proxmox Server and Using AMD GPUs with ollama
Back in the day I tried deploying open-webui as a container on my old proxmox server and the performance was abysmal. So during the holiday season I decided to get a new server with a GPU (I picked HP Z2 Mini G1a) and try running open-webui one more time.
Migrate VMs to new Proxmox Server
I was planning on decommissioning the original server so I didn’t want to enable HA and live migrate the VMs. I did find other people mentioning that this migration can be done by using backups:
I had some VMs that used a local drive and another drive that is connected to the iSCSI storage. So I found backup single disk in VM and we can edit a disk we don’t want to backup (In my case it was the one connected to the iSCSI storage):
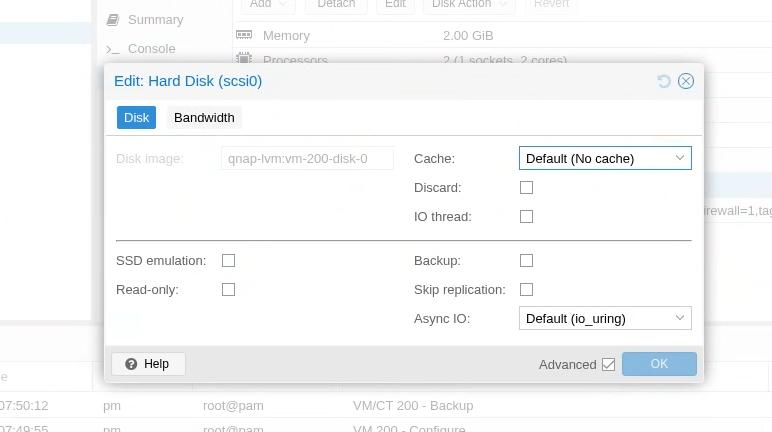
Then I took a backup and saved it to my NFS share (which I connected to both):
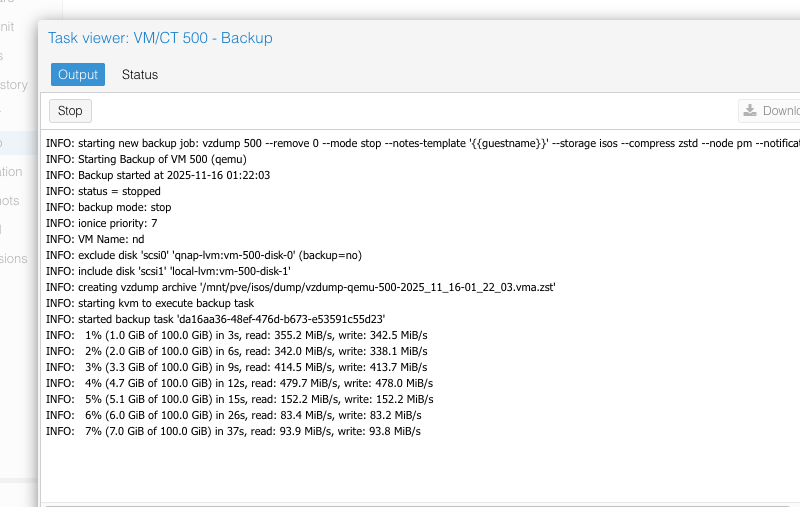
Then on the destination host, I restored from the backup:
To reconnect the drive that was on the iSCSI shared storage, I already saw the disk on the new host (since I readded the iSCSI target already):
> sudo lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data pve twi-aotz-- <347.90g 8.28 0.69
root pve -wi-ao---- 96.00g
swap pve -wi-ao---- 8.00g
vm-101-disk-0 pve Vwi-aotz-- 100.00g data 28.80
vm-200-disk-0 qnap -wi-ao---- 25.00g
vm-300-disk-0 qnap -wi-a----- 50.00g
vm-400-disk-0 qnap -wi-a----- 50.00g
vm-500-disk-0 qnap -wi-a----- 50.00g
Then, as per How do you attach a disk to a VM? I had to modify the /etc/pve/qemu-server/VMID.conf file to add those back. Then in the UI I saw the disk attached. I powered on the VM and the migration was successful.
Enabling GPU Passthrough
I ran into a bunch of guides for this:
- VM iGPU Passthrough
- ryzen-gpu-passthrough-proxmox
- AMD Ryzen 9 AI HX 370 iGPU Passthrough
- How to setup Proxmox 9 with GPU passthrough to an Ubuntu 25 VM (to use Ollama/Steam) on Strix Halo Max 395+
- Strix Halo GPU Passthrough on Proxmox 9 (AI Max+ 395)
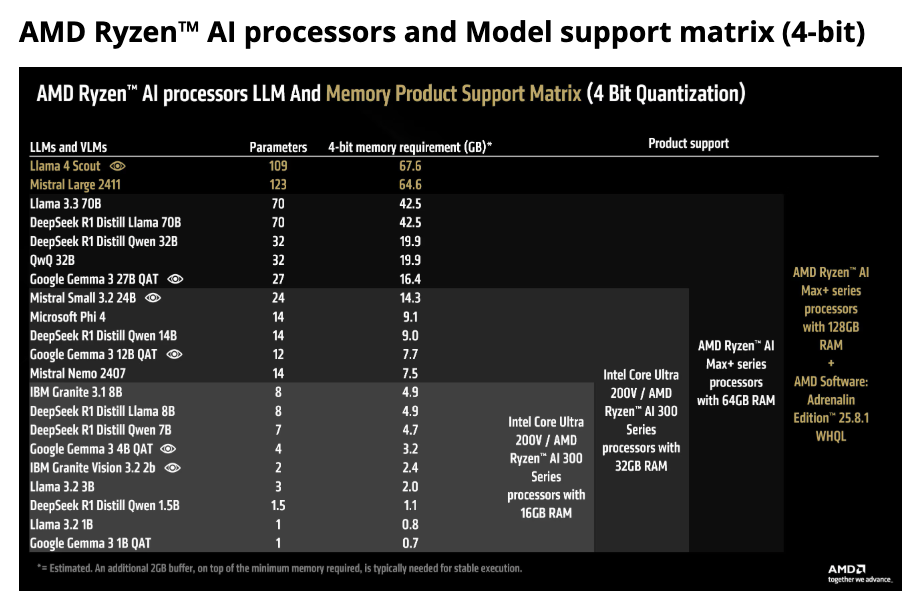
The server had 128GB of RAM and I needed to decided how much memory to give to the GPU. From FAQs: AMD Variable Graphics Memory, VRAM, AI Model Sizes, Quantization, MCP and More!, the machine has 128GB total but that is shared across the system and the GPU:
Reviewing Choosing the Right NVIDIA GPU for LLMs on the Ollama Platform:

It looks like with 64GB, I should be able to handle 70B parameter models, which can handle advanced coding. Just for reference here is break down of the different use cases for the LLM models based on size:
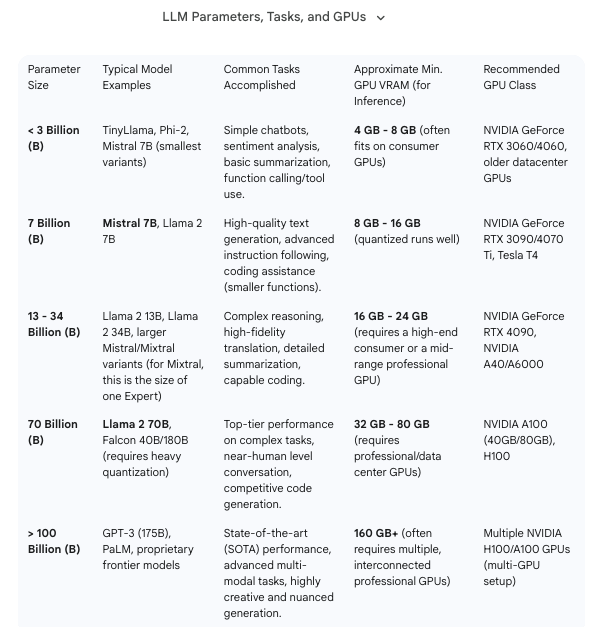
So I decided to just split it 64GB for system and 64GB for GPU:
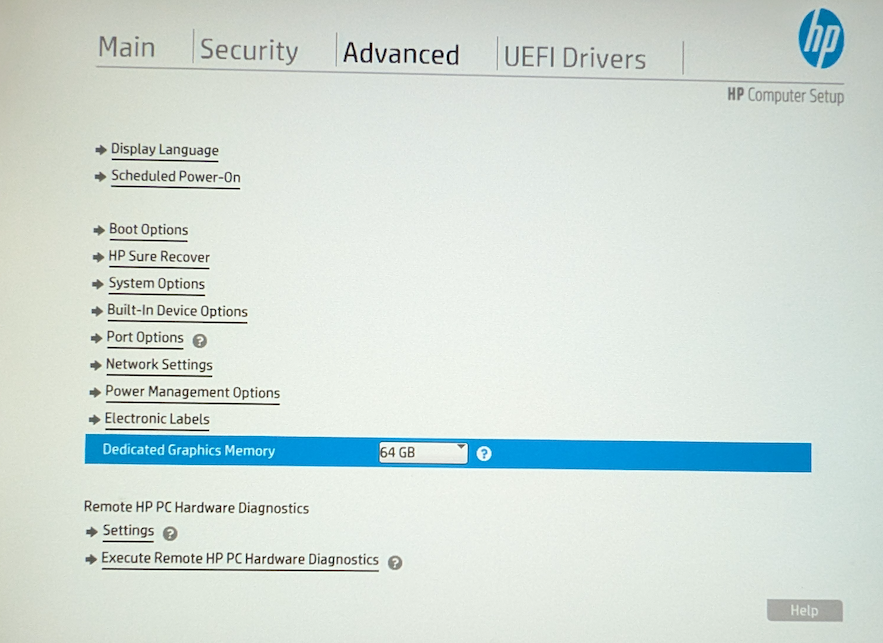
And I also confirmed all the SVM (AMD-Vi) and iommu (DAM protection) settings are enabled:
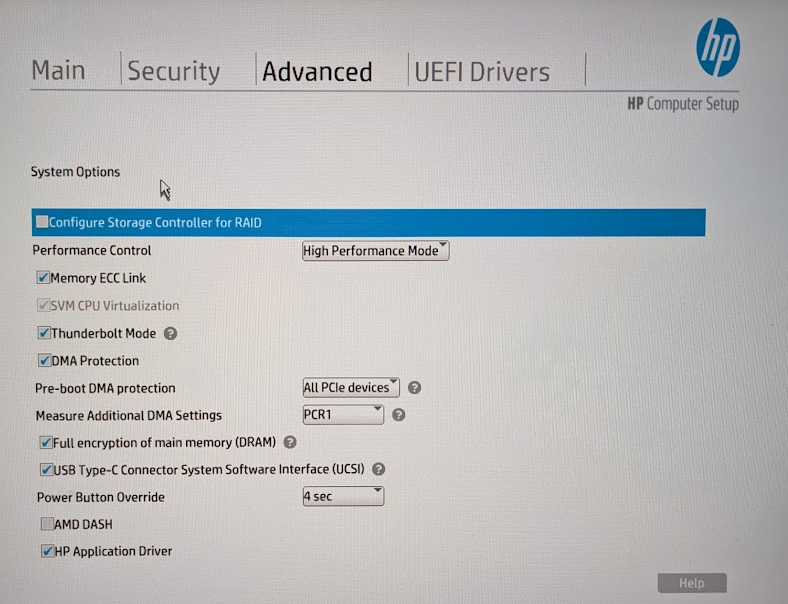
Let’s break down the rest into separate sections.
Configuring the Proxmox Server for GPU Passthrough
The above guides cover the steps well. Here is what I ended up with:
## the GPU PCI devices
> lspci -nn | grep -e 'AMD/ATI'
c4:00.0 Display controller [0380]: Advanced Micro Devices, Inc. [AMD/ATI] Strix Halo [Radeon Graphics / Radeon 8050S Graphics / Radeon 8060S Graphics] [1002:1586] (rev d1)
c4:00.1 Audio device [0403]: Advanced Micro Devices, Inc. [AMD/ATI] Radeon High Definition Audio Controller [Rembrandt/Strix] [1002:1640]
## blacklist
> cat /etc/modprobe.d/blacklist-gpu.conf
blacklist radeon
blacklist amdgpu
blacklist snd_hda_intel
## VFIO settings
> cat /etc/modprobe.d/vfio.conf
options vfio-pci ids=1002:1640,1002:1586 disable_vga=1
softdep radeon pre: vfio-pci
softdep amdgpu pre: vfio-pci
softdep snd_hda_intel pre: vfio-pci
> cat /etc/modules-load.d/vfio.conf
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
## GRUB
> grep GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet iommu=pt initcall_blacklist=sysfb_init"
To apply all settings:
update-initramfs -u -k all
update-grub
systemctl reboot
After the reboot you should see the following in dmesg:
> sudo dmesg | grep -e DMAR -e IOMMU -e AMD-Vi
[ 0.117853] AMD-Vi: ivrs, add hid:AMDI0020, uid:ID00, rdevid:0xa0
[ 0.117854] AMD-Vi: ivrs, add hid:AMDI0020, uid:ID01, rdevid:0xa0
[ 0.117855] AMD-Vi: ivrs, add hid:AMDI0020, uid:ID02, rdevid:0xa0
[ 0.117855] AMD-Vi: ivrs, add hid:AMDI0020, uid:ID03, rdevid:0xa0
[ 0.117856] AMD-Vi: ivrs, add hid:MSFT0201, uid:1, rdevid:0x60
[ 0.117857] AMD-Vi: ivrs, add hid:AMDI0020, uid:ID04, rdevid:0xa0
[ 0.117857] AMD-Vi: Using global IVHD EFR:0x246577efa2254afa, EFR2:0x10
[ 3.183138] pci 0000:00:00.2: AMD-Vi: IOMMU performance counters supported
[ 3.184553] AMD-Vi: Extended features (0x246577efa2254afa, 0x10): PPR NX GT [5] IA GA PC GA_vAPIC
[ 3.184557] AMD-Vi: Interrupt remapping enabled
[ 3.184697] AMD-Vi: Virtual APIC enabled
[ 3.186583] perf/amd_iommu: Detected AMD IOMMU #0 (2 banks, 4 counters/bank).
and the iommu groups:
> find /sys/kernel/iommu_groups/ -type l
/sys/kernel/iommu_groups/17/devices/0000:c3:00.0
/sys/kernel/iommu_groups/7/devices/0000:00:02.5
/sys/kernel/iommu_groups/25/devices/0000:c5:00.1
/sys/kernel/iommu_groups/15/devices/0000:c1:00.0
/sys/kernel/iommu_groups/5/devices/0000:00:02.1
/sys/kernel/iommu_groups/23/devices/0000:c4:00.6
You also won’t see any /dev/dri or /dev/kfd devices:
root@pa:~# ls /dev/dri
ls: cannot access '/dev/dri': No such file or directory
root@pa:~# ls -l /dev/kfd
ls: cannot access '/dev/kfd': No such file or directory
One note, as soon as you enable initcall_blacklist=sysfb_init, during boot it won’t show the regular boot up steps, it will just look like it hangs at Loading initial ramdisk.., but that’s expected behavior (there is a similar comment on Display output stuck Loading initial ramdisk…… but boot regurarly). Just wait some time and make sure you can ping the server.
Update VM Settings
From the above guides, I ended up updating the following settings:
# diff --side-by-side --suppress-common-lines /etc/pve/qemu-server/103.conf ~backup/103.conf
bios: ovmf <
efidisk0: local-lvm:vm-103-disk-1,efitype=4m,ms-cert=2023,pre <
hostpci0: 0000:c4:00.0,pcie=1,romfile=vbios_8060s.bin,x-vga=1 <
hostpci1: 0000:c4:00.1,pcie=1,romfile=AMDGopDriver.rom <
machine: q35 <
memory: 24576 | memory: 8192
Updating Linux from SeaBios to EUFI
After the switch the OS wouln’t boot:

And this is expected since we need a new partition in the OS to hold the boot information. I had to get creative to create a brand new /boot/efi partition. Basically delete /dev/sda2 which was the original /boot (first back up the contents to /home). Then create two new partitions:
/dev/sda2 1G -> /boot/efi
/dev/sda4 1G -> /boot
Here is how the final layout looked like:
> sudo fdisk -l /dev/sda
Disk /dev/sda: 50 GiB, 53687091200 bytes, 104857600 sectors
Disk model: QEMU HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 44B9DDF5-B865-4B1C-BAAB-7A03DC15ABE2
Device Start End Sectors Size Type
/dev/sda1 2048 4095 2048 1M BIOS boot
/dev/sda2 4096 2101247 2097152 1G EFI System
/dev/sda3 4198400 104855551 100657152 48G Linux filesystem
/dev/sda4 2101248 3739647 1638400 800M Linux filesystem
Partition table entries are not in disk order.
Then had to reinstall grub with efi. From a live cd:
mount /dev/mapper/debian-vg-root /mnt
mount /dev/sda4 /mnt/boot
## Copy the backed up files to /mnt/boot
rsync -avzP /backup/boot/. /mnt/boot/.
mount /dev/sda2 /mnt/boot/efi
mount --bind /proc /mnt/proc
mount --bind /sys /mnt/sys
mount --bind /dev /mnt/dev
chroot /mnt
mount -t efivarfs efivarfs /sys/firmware/efi/efivars
### confirm you see EFI vars
apt remove grub-pc
apt install grub-efi efibootmgr
efibootmgr -v
### then install grub
grub-install --target=x86_64-efi --efi-directory /boot/efi
Also since I updated the partition schema, I had to update /etc/fstab and recreate the initramfs
## get the uuids
blkid
# update the partitions /etc/fstab
vi /etc/fstab
# update the initiramfs
update-initramfs -u -k all
I also ran into these pretty awesome guides
- Switch Debian from legacy to UEFI boot mode
- Move your Linux from legacy BIOS to UEFI in place with minimal downtime
They cover the conversion in more depth and also cover the converion to a gpt type partition table (which luckily I didn’t have to do). After all of those changes, the the OS finally booted
Updating to Debian 13
After the OS booted up, the GPU wouldn’t load. Forgot to keep the logs, but I searched for this and I saw a bunch of errors.
dmesg | grep -i gpu
Doing a Google search it was recommened to get a newer kernel, so I updated from debian 1.12 to 1.13 following instructions in Debian 12 (Bookworm) to Debian 13 (Trixie) Upgrade Guide:
### clean up
sudo apt clean
sudo apt autoremove --purge
### update debian 12
sudo apt update && sudo apt full-upgrade
### Convert sources
sudo sed -i 's/bookworm/trixie/g' /etc/apt/sources.list
find /etc/apt/sources.list.d -name "*.list" -exec sudo sed -i 's/bookworm/trixie/g' {} \;
### upgrade to debian 13
sudo apt update
sudo apt full-upgrade
After doing this, I ran into a weird issue where the disk devices would load and all my disks under /dev/sd* were gone:
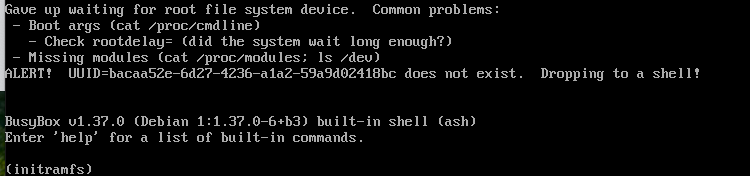
After a bunch of troubleshooting, it ended up the iommu flag that some of the above guides recommended:
machine: q35,viommu=virtio
I removed that flag and then the OS booted. If booted into the old kernel from debian 12, it actually worked (must be incompatibilty between the new kernel and that flag). And I was able to see the gpu:
> sudo dmesg | grep gpu
[ 5.631483] [drm] amdgpu kernel modesetting enabled.
[ 5.631662] amdgpu: Virtual CRAT table created for CPU
[ 5.631675] amdgpu: Topology: Add CPU node
[ 5.634399] amdgpu 0000:01:00.0: amdgpu: Fetched VBIOS from VFCT
[ 5.634402] amdgpu: ATOM BIOS: 113-STRXLGEN-001
[ 5.702347] amdgpu 0000:01:00.0: amdgpu: VPE: collaborate mode true
[ 5.702379] amdgpu 0000:01:00.0: amdgpu: Trusted Memory Zone (TMZ) feature disabled as experimental (default)
[ 5.702449] amdgpu 0000:01:00.0: amdgpu: VRAM: 65536M 0x0000008000000000 - 0x0000008FFFFFFFFF (65536M used)
[ 5.702452] amdgpu 0000:01:00.0: amdgpu: GART: 512M 0x00007FFF00000000 - 0x00007FFF1FFFFFFF
[ 5.702693] [drm] amdgpu: 65536M of VRAM memory ready
[ 5.702696] [drm] amdgpu: 12009M of GTT memory ready.
[ 5.702710] [drm] GART: num cpu pages 131072, num gpu pages 131072
[ 5.729910] amdgpu 0000:01:00.0: amdgpu: reserve 0x8c00000 from 0x8fe0000000 for PSP TMR
[ 6.412952] amdgpu 0000:01:00.0: amdgpu: RAS: optional ras ta ucode is not available
[ 6.416654] amdgpu 0000:01:00.0: amdgpu: RAP: optional rap ta ucode is not available
[ 6.416657] amdgpu 0000:01:00.0: amdgpu: SECUREDISPLAY: securedisplay ta ucode is not available
[ 6.451036] amdgpu 0000:01:00.0: amdgpu: SMU is initialized successfully!
[ 6.487925] amdgpu 0000:01:00.0: amdgpu: MES FW version must be >= 0x7f to enable LR compute workaround.
[ 6.498250] kfd kfd: amdgpu: Allocated 3969056 bytes on gart
[ 6.498265] kfd kfd: amdgpu: Total number of KFD nodes to be created: 1
[ 6.498940] amdgpu: Virtual CRAT table created for GPU
[ 6.500084] amdgpu: Topology: Add dGPU node [0x1586:0x1002]
[ 6.500087] kfd kfd: amdgpu: added device 1002:1586
[ 6.500098] amdgpu 0000:01:00.0: amdgpu: SE 2, SH per SE 2, CU per SH 10, active_cu_number 40
[ 6.500102] amdgpu 0000:01:00.0: amdgpu: ring gfx_0.0.0 uses VM inv eng 0 on hub 0
[ 6.500103] amdgpu 0000:01:00.0: amdgpu: ring comp_1.0.0 uses VM inv eng 1 on hub 0
[ 6.500104] amdgpu 0000:01:00.0: amdgpu: ring comp_1.1.0 uses VM inv eng 4 on hub 0
[ 6.500105] amdgpu 0000:01:00.0: amdgpu: ring comp_1.2.0 uses VM inv eng 6 on hub 0
[ 6.500105] amdgpu 0000:01:00.0: amdgpu: ring comp_1.3.0 uses VM inv eng 7 on hub 0
[ 6.500106] amdgpu 0000:01:00.0: amdgpu: ring comp_1.0.1 uses VM inv eng 8 on hub 0
[ 6.500106] amdgpu 0000:01:00.0: amdgpu: ring comp_1.1.1 uses VM inv eng 9 on hub 0
[ 6.500106] amdgpu 0000:01:00.0: amdgpu: ring comp_1.2.1 uses VM inv eng 10 on hub 0
[ 6.500107] amdgpu 0000:01:00.0: amdgpu: ring comp_1.3.1 uses VM inv eng 11 on hub 0
[ 6.500107] amdgpu 0000:01:00.0: amdgpu: ring sdma0 uses VM inv eng 12 on hub 0
[ 6.500108] amdgpu 0000:01:00.0: amdgpu: ring vcn_unified_0 uses VM inv eng 0 on hub 8
[ 6.500108] amdgpu 0000:01:00.0: amdgpu: ring vcn_unified_1 uses VM inv eng 1 on hub 8
[ 6.500109] amdgpu 0000:01:00.0: amdgpu: ring jpeg_dec_0 uses VM inv eng 4 on hub 8
[ 6.500109] amdgpu 0000:01:00.0: amdgpu: ring jpeg_dec_1 uses VM inv eng 6 on hub 8
[ 6.500110] amdgpu 0000:01:00.0: amdgpu: ring mes_kiq_3.1.0 uses VM inv eng 13 on hub 0
[ 6.500110] amdgpu 0000:01:00.0: amdgpu: ring vpe uses VM inv eng 7 on hub 8
[ 6.504583] amdgpu 0000:01:00.0: amdgpu: Runtime PM not available
[ 6.505807] [drm] Initialized amdgpu 3.61.0 for 0000:01:00.0 on minor 1
[ 6.512988] amdgpu 0000:01:00.0: [drm] fb1: amdgpudrmfb frame buffer device
Post Debian 13 issues
Then inside the VM, kubelet failed to start:
Nov 17 13:35:47 ma kubelet[1347]: E1117 13:35:47.730947 1347 kubelet.go:1688] "Failed to start ContainerManager" err="[invalid kernel flag: vm/overcommit_memory, expected value: 1, actual value: 0, invalid kernel flag: kernel/panic, expected value: 10, actual value: 0, invalid kernel flag: kernel/panic_on_oops, expected value: 1, actual value: 0]"
The upgrade removed the previous sysctl config, but it luckily backed it up, so to fix it:
sudo cp /etc/sysctl.conf.dpkg-bak /etc/sysctl.d/20-k8s.conf
sudo sysctl --system
Getting Ollama working on the VM
Next I wanted to make sure ollama is able to use the GPUs. The first challenge is to make sure the OS sees the GPUs. A good tool for that is rocminfo or nvtop:
> sudo rocminfo
ROCk module is NOT loaded, possibly no GPU devices
> sudo nvtop
No GPU to monitor.
When using AMD GPUs, we have to use amdgpu and rocm. First let’s confirm our GPU is supported, from Linux support matrices by ROCm version

It does cover my GPU, then coincidentally I ran into this issue and it describes the steps to install on debian 13. The best thing to do is to just intall the amdgpu driver as per Quick start installation guide:
wget https://repo.radeon.com/amdgpu-install/7.1/ubuntu/noble/amdgpu-install_7.1.70100-1_all.deb
sudo apt install ./amdgpu-install_7.1.70100-1_all.deb
sudo apt update
sudo apt install "linux-headers-$(uname -r)"
sudo apt install amdgpu-dkms
And then update the grub config as per comment #1, here is what I had to make sure I allocate 64GB:
> cat /etc/default/grub.d/amdgpu.cfg
# /etc/default/grub.d/amdgpu.cfg
GRUB_CMDLINE_LINUX="${GRUB_CMDLINE_LINUX:+$GRUB_CMDLINE_LINUX }amdgpu.gttsize=65536 ttm.pages_limit=16777216 amdgpu.cwsr_enable=0"
Then after rebooting the VM should see GPUs and no more MES messages:
amdgpu 0000:01:00.0: amdgpu: MES FW version must be >= 0x7f to enable LR compute workaround.
Check out comment #2 for the full dmesg output of healthy amdgpu loading of the GPU devices. And the memory is allocated correctly:
> sudo dmesg | grep "amdgpu.*memory"
[ 10.906499] [drm] amdgpu: 65536M of VRAM memory ready
[ 10.906502] [drm] amdgpu: 65536M of GTT memory ready.
Installing ollama with rocm
The ollama install instructions cover the steps:
sudo mkdir /usr/local/ollama
### install ollama
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tgz \
| sudo tar zx -C /usr/local/ollama
### install rocm
curl -fsSL https://ollama.com/download/ollama-linux-amd64-rocm.tgz \
| sudo tar zx -C /usr/local/ollama
### create the symlink
sudo ln -s /usr/local/ollama/bin/ollama /usr/local/bin/ollama
Then if everything is working you should see ollama find the GPU:
> export OLLAMA_DEBUG=1
> ollama serve
time=2025-11-18T21:50:29.850Z level=INFO source=routes.go:1544 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:DEBUG OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_REMOTES:[ollama.com] OLLAMA_SCHED_SPREAD:false OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-11-18T21:50:29.868Z level=INFO source=images.go:522 msg="total blobs: 5"
time=2025-11-18T21:50:29.870Z level=INFO source=images.go:529 msg="total unused blobs removed: 0"
time=2025-11-18T21:50:29.873Z level=INFO source=routes.go:1597 msg="Listening on [::]:11434 (version 0.12.11)"
time=2025-11-18T21:50:29.874Z level=DEBUG source=sched.go:120 msg="starting llm scheduler"
time=2025-11-18T21:50:29.875Z level=INFO source=runner.go:67 msg="discovering available GPUs..."
time=2025-11-18T21:50:29.878Z level=INFO source=server.go:392 msg="starting runner" cmd="/usr/bin/ollama runner --ollama-engine --port 36581"
time=2025-11-18T21:50:29.878Z level=DEBUG source=server.go:393 msg=subprocess PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin LD_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/rocm:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 OLLAMA_HOST=0.0.0.0:11434 OLLAMA_DEBUG=1 OLLAMA_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/rocm
time=2025-11-18T21:50:30.387Z level=DEBUG source=runner.go:418 msg="bootstrap discovery took" duration=511.04519ms OLLAMA_LIBRARY_PATH="[/usr/lib/ollama /usr/lib/ollama/rocm]" extra_envs=map[]
time=2025-11-18T21:50:30.387Z level=DEBUG source=runner.go:116 msg="evluating which if any devices to filter out" initial_count=1
time=2025-11-18T21:50:30.387Z level=DEBUG source=runner.go:128 msg="verifying device is supported" library=/usr/lib/ollama/rocm description="AMD Radeon Graphics" compute=gfx1151 id=0 pci_id=0000:01:00.0
time=2025-11-18T21:50:30.388Z level=INFO source=server.go:392 msg="starting runner" cmd="/usr/bin/ollama runner --ollama-engine --port 44781"
time=2025-11-18T21:50:30.388Z level=DEBUG source=server.go:393 msg=subprocess PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin LD_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/rocm:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 OLLAMA_HOST=0.0.0.0:11434 OLLAMA_DEBUG=1 OLLAMA_LIBRARY_PATH=/usr/lib/ollama:/usr/lib/ollama/rocm ROCR_VISIBLE_DEVICES=0 GGML_CUDA_INIT=1
time=2025-11-18T21:50:30.944Z level=DEBUG source=runner.go:418 msg="bootstrap discovery took" duration=556.333456ms OLLAMA_LIBRARY_PATH="[/usr/lib/ollama /usr/lib/ollama/rocm]" extra_envs="map[GGML_CUDA_INIT:1 ROCR_VISIBLE_DEVICES:0]"
time=2025-11-18T21:50:30.944Z level=DEBUG source=runner.go:175 msg="adjusting filtering IDs" FilterID=0 new_ID=0
time=2025-11-18T21:50:30.944Z level=DEBUG source=runner.go:40 msg="GPU bootstrap discovery took" duration=1.070181506s
time=2025-11-18T21:50:30.944Z level=INFO source=types.go:42 msg="inference compute" id=0 filter_id=0 library=ROCm compute=gfx1151 name=ROCm0 description="AMD Radeon Graphics" libdirs=ollama,rocm driver=60342.13 pci_id=0000:01:00.0 type=iGPU total="64.0 GiB" available="63.8 GiB"
This is the important line:
time=2025-11-18T21:50:30.944Z level=INFO source=types.go:42 msg="inference compute" id=0 filter_id=0 library=ROCm compute=gfx1151 name=ROCm0 description="AMD Radeon Graphics" libdirs=ollama,rocm driver=60342.13 pci_id=0000:01:00.0 type=iGPU total="64.0 GiB" available="63.8 GiB"
(Optional) Confirming with ROCM the GPUs are loaded
After adding the amdgpu-install_7.1.70100-1_all.deb package, this add an apt repo and we can install other tools as well:
> sudo apt search rocminfo
rocminfo/stable,now 6.1.2-2 amd64 [installed]
ROCm Application for Reporting System Info
> sudo apt search rocm-smi
rocm-smi/stable 6.1.2-1 amd64
ROCm System Management Interface (ROCm SMI) command-line interface
And here is the output:
$ rocm-smi
========================================= ROCm System Management Interface =========================================
=================================================== Concise Info ===================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Edge) (Socket) (Mem, Compute, ID)
====================================================================================================================
0 1 0x1586, 51259 36.0°C 23.039W N/A, N/A, 0 N/A 1000Mhz 0% auto N/A 34% 0%
====================================================================================================================
=============================================== End of ROCm SMI Log ================================================
Check out the full output of rocminfo in comment #2
Pass through GPU to open-webui
I ran into:
- Running Ollama and Open WebUI Self-Hosted With AMD GPU
- UnexpectedAdmissionError with Nvidia GPU Operator
And those helped me define my value.yaml for the open-webui helm chart. Initially I had the following:
> cat values.yaml
ollama:
enabled: true
ollama:
gpu:
enabled: true
type: amd
nodeSelector:
kubernetes.io/hostname: ma
podSecurityContext:
runAsUser: 0
runAsGroup: 0
extraEnv:
- name: OLLAMA_DEBUG
value: 1
## volumes
volumes:
- name: dev-dri
hostPath:
path: /dev/dri
- name: dev-kfd
hostPath:
path: /dev/kfd
## volumeMounts
volumeMounts:
- mountPath: /dev/dri
name: dev-dri
mountPropagation: HostToContainer
- mountPath: /dev/kfd
name: dev-kfd
mountPropagation: HostToContainer
But that failed to use the GPUs. So I went into the container:
> k exec -it open-webui-ollama-7f587d8fc-w6wt7 -- /bin/bash
root@open-webui-ollama-7f587d8fc-w6wt7:/# apt update
root@open-webui-ollama-7f587d8fc-w6wt7:/# apt install rocminfo
root@open-webui-ollama-7f587d8fc-w6wt7:/# rocminfo
ROCk module is loaded
Unable to open /dev/kfd read-write: Operation not permitted
Failed to get user name to check for video group membership
And that helped me troubleshoot the issue (I needed to set privileged: true for the securityContext), and I ended up with the following:
> cat values.yaml
ollama:
enabled: true
ollama:
gpu:
enabled: true
type: amd
nodeSelector:
kubernetes.io/hostname: ma
securityContext:
privileged: true
podSecurityContext:
runAsUser: 0
runAsGroup: 0
extraEnv:
- name: OLLAMA_DEBUG
value: 1
## volumes
volumes:
- name: dev-dri
hostPath:
path: /dev/dri
- name: dev-kfd
hostPath:
path: /dev/kfd
## volumeMounts
volumeMounts:
- mountPath: /dev/dri
name: dev-dri
mountPropagation: HostToContainer
- mountPath: /dev/kfd
name: dev-kfd
mountPropagation: HostToContainer
Then after that the pod was able to recongize the GPU
Using the models
I reviewed Code editing leaderboard and I decided to use the gemma2:27b-instruct-q8_0 model and after loading it, it did really well. First I tried a smaller model:
And we can see it took 3 seconds. Then I tried gemma2:27b-instruct-q8_0 and it was the same:
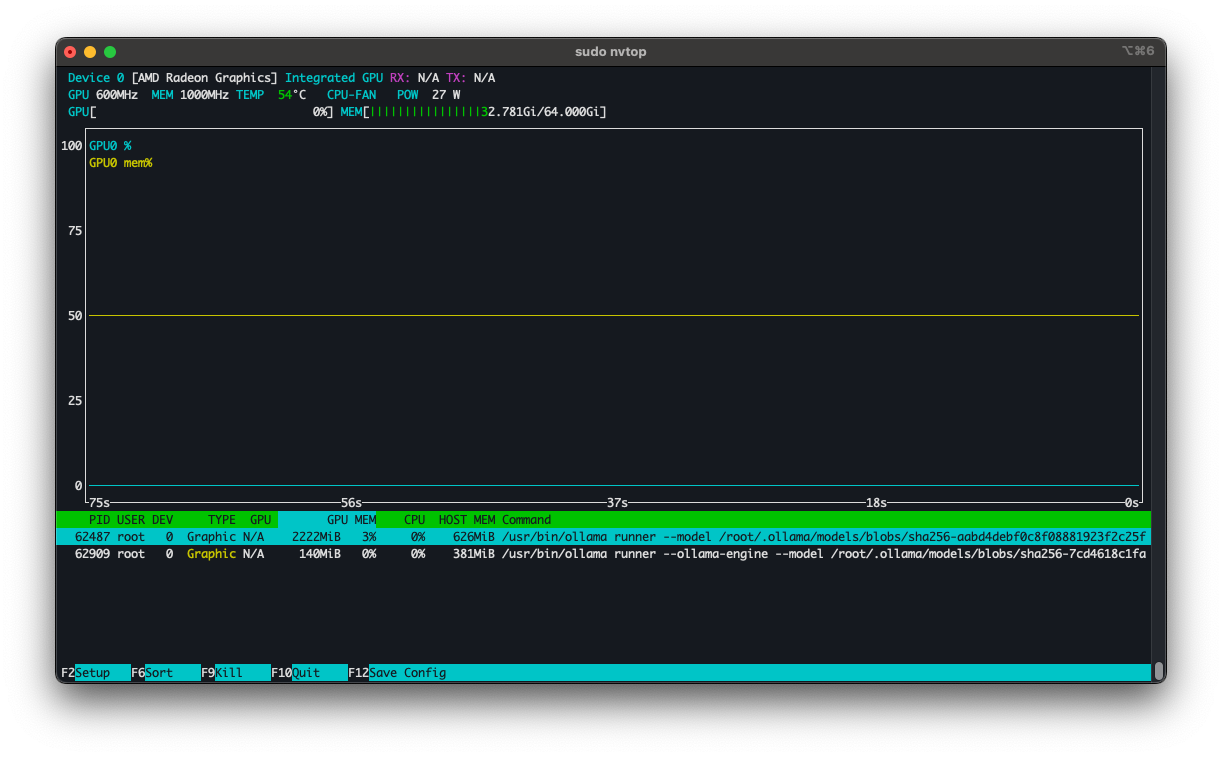
I also looked at nvtop and I saw the GPU RAM used at ~32GB (30GB for gemma and 2 GB for deepseek):
Random Ollama notes
Whenever I would download a huge model, it would take a while. To manually download and test connectivity:
export OLLAMA_MODELS=/mnt/pve/isos/shared-pvs/default/open-webui-ollama/models
ollama serve &
ollama pull gemma2:27b-instruct-q8_0
Also whenever I use a model for the first time it would take a while to load. So if you have a slow disk it might “take a minute”. Also I noticed my model was getting reloaded, then I reviewed the logs and I saw the following:
time=2025-11-19T03:21:36.575Z level=DEBUG source=sched.go:292 msg="timer expired, expiring to unload" runner.name=registry.ollama.ai/library/gemma2:27b-instruct-q8_0 runner.inference="[{ID:0 Library:ROCm}]" runner.size="28.9 GiB" runner.vram="28.9 GiB" runner.parallel=1 runner.pid=46 runner.model=/root/.ollama/models/blobs/sha256-1b971f02fb8f2cb34d37f83dcd1d9cc982cb1b3701d0a169e45fcd8fed0750d6 runner.num_ctx=4096
It looks like ollama expires a model if it’s idle. There are flags we can use:
OLLAMA_KEEP_ALIVE=30m ollama serve
Or indefinitely:
OLLAMA_KEEP_ALIVE=-1
I also noticed my VM became pretty sluggish after some time:
> uptime
17:51:28 up 4:39, 2 users, load average: 396.04, 396.16, 396.27
I looked at dmesg and saw the following:
[ 242.700006] INFO: task kworker/0:5:4069 blocked for more than 120 seconds.
[ 242.700015] Tainted: G OE 6.12.57+deb13-amd64 #1 Debian 6.12.57-1
[ 242.700022] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 242.700028] task:kworker/0:5 state:D stack:0 pid:4069 tgid:4069 ppid:2 flags:0x00004000
[ 242.700031] Workqueue: events amdgpu_tlb_fence_work [amdgpu]
[ 242.700113] Call Trace:
[ 242.700114] <TASK>
[ 242.700114] __schedule+0x505/0xc00
[ 242.700116] schedule+0x27/0xf0
[ 242.700117] schedule_timeout+0x12f/0x160
[ 242.700119] dma_fence_default_wait+0x1e5/0x260
[ 242.700120] ? __pfx_dma_fence_default_wait_cb+0x10/0x10
[ 242.700121] dma_fence_wait_timeout+0x108/0x140
[ 242.700122] amdgpu_tlb_fence_work+0x2c/0xe0 [amdgpu]
[ 242.700269] process_one_work+0x174/0x330
[ 242.700274] worker_thread+0x251/0x390
[ 242.700276] ? __pfx_worker_thread+0x10/0x10
[ 242.700277] kthread+0xcf/0x100
[ 242.700278] ? __pfx_kthread+0x10/0x10
[ 242.700279] ret_from_fork+0x31/0x50
[ 242.700280] ? __pfx_kthread+0x10/0x10
[ 242.700281] ret_from_fork_asm+0x1a/0x30
[ 242.700285] </TASK>
And I noticed a bunch of kworkerd processes stuck:
> ps -eo pid,user,stat,comm,wchan,cpu,etime | grep D | wc -l
534
This looks like a known issue: ROCm Driver hangs kworkers when using ollama and it should be fixed in the 6.17.8 kernel. Someone also mentioned that using vulkan can help out. I tried to install the vulkan enabled amdgpu module, but it failed:
> sudo amdgpu-install --usecase=dkms --vulkan=radv
Hit:1 http://deb.debian.org/debian trixie InRelease
Hit:2 http://security.debian.org/debian-security trixie-security InRelease
Hit:3 http://deb.debian.org/debian trixie-updates InRelease
Hit:4 https://apt.postgresql.org/pub/repos/apt trixie-pgdg InRelease
Hit:5 https://repo.radeon.com/amdgpu/30.20/ubuntu noble InRelease
Hit:6 https://repo.radeon.com/rocm/apt/7.1 noble InRelease
Hit:7 https://repo.radeon.com/graphics/7.1/ubuntu noble InRelease
Reading package lists... Done
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
amdgpu-dkms is already the newest version (1:6.16.6.30200000-2238411.24.04).
linux-headers-6.12.57+deb13-amd64 is already the newest version (6.12.57-1).
Solving dependencies... Error!
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
mesa-amdgpu-vulkan-drivers : Depends: libdisplay-info1 (>= 0.1.1) but it is not installable
E: Unable to correct problems, you have held broken packages.
E: The following information from --solver 3.0 may provide additional context:
Unable to satisfy dependencies. Reached two conflicting decisions:
1. mesa-amdgpu-vulkan-drivers:amd64=1:25.3.0.70100-2238427.24.04 is selected for install
2. mesa-amdgpu-vulkan-drivers:amd64 Depends libdisplay-info1 (>= 0.1.1)
but none of the choices are installable:
[no choices]
As per this comment, trying the latest debian version forky worked out. Here is the kernel version at the time:
~$ uname -a
Linux ub 6.17.8+deb14-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.17.8-1 (2025-11-15) x86_64 GNU/Linux
And I ran the following to start ollama:
export OLLAMA_DEBUG=1
export OLLAMA_VULKAN=1
export OLLAMA_HOST=0.0.0.0
export OLLAMA_KEEP_ALIVE=-1
ollama serve
For now I will configure the helm chart to point to an external server:
> head values.yaml
ollamaUrls:
- "http://deb.kar.int:11434"
ollama:
enabled: false
And when stable debian gets to that kernel version I will switch over.