Migrate Google Sites to Confluence
The first thing we have to do is export the google sites content.
Use Google Sites Liberation to Export Google Sites
There is a tool called google-sites-liberation which takes care of that for us. Here is the link to the program and here is a snippet from the site on what the tool does:
This is an import/export tool for Google Sites. Using HTML Microformats it generates an XHTML version of Sites content suitable for offline browsing and simple HTTP hosting, which is also able to be losslessly imported back into sites.
So let’s go ahead and download the program:
elatov@fed:/opt/work/mig$wget https://google-sites-liberation.googlecode.com/files/google-sites-liberation-1.0.4.jar
--2014-07-26 09:48:58-- https://google-sites-liberation.googlecode.com/files/google-sites-liberation-1.0.4.jar
Resolving google-sites-liberation.googlecode.com (google-sites-liberation.googlecode.com)... 74.125.28.82, 2607:f8b0:400e:c02::52
Connecting to google-sites-liberation.googlecode.com (google-sites-liberation.googlecode.com)|74.125.28.82|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4799363 (4.6M) [application/x-java-archive]
Saving to: ‘google-sites-liberation-1.0.4.jar’
100%[======================================>] 4,799,363 419KB/s in 12s
2014-07-26 09:49:10 (407 KB/s) - ‘google-sites-liberation-1.0.4.jar’ saved [4799363/4799363]
I already had java installed:
elatov@fed:/opt/work/mig$java -version
java version "1.7.0_65"
OpenJDK Runtime Environment (fedora-2.5.1.3.fc20-x86_64 u65-b17)
OpenJDK 64-Bit Server VM (build 24.65-b04, mixed mode)
So running the following started up the program:
elatov@fed:/opt/work/mig$java -jar google-sites-liberation-1.0.4.jar
and I saw the following:
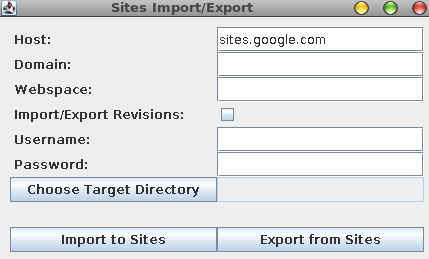
Then go ahead and fill out your sites information. Here is an example from the original site:
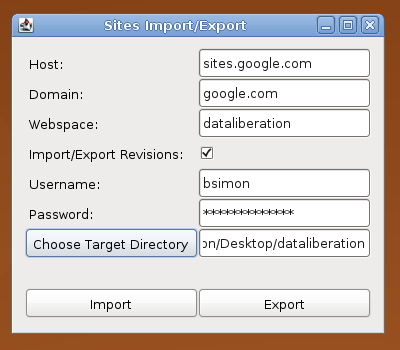
After everything is filled out click in Export from Sites and you will see the progress of the export:
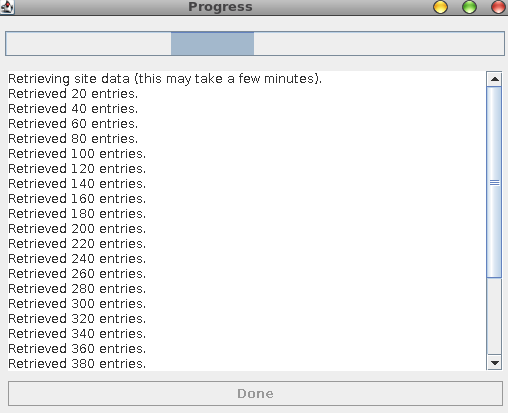
After it’s done you will have a folder with all of your google sites broken down by folders for each page (and if you had sub pages, those would broken down into sub folders).
Convert XHTML Google Sites into Markdown
There is already a tool called sites-to-markdown, here is a link to that program. So let’s go ahead and download the software:
elatov@fed:/opt/work/mig$git clone https://github.com/foursquare/sites-to-markdown.git
Cloning into 'sites-to-markdown'...
remote: Reusing existing pack: 17, done.
Unpacking objects: 100% (17/17), done.
remote: Total 17 (delta 0), reused 0 (delta 0)
Checking connectivity... done.
There are a couple of prereqs for this software, from the main page:
Requirements
- java 1.7
- maven
I already had java, so let’s install maven:
elatov@fed:~$sudo yum install maven
Here was the maven version that was installed:
elatov@fed:~$mvn --version
Apache Maven 3.1.1 (NON-CANONICAL_2013-11-08_14-32_mockbuild; 2013-11-08 07:32:41-0700)
Maven home: /usr/share/maven
Java version: 1.7.0_65, vendor: Oracle Corporation
Java home: /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65-2.5.1.3.fc20.x86_64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.15.6-200.fc20.x86_64", arch: "amd64", family: "unix"
From the main site, here is the usage:
Usage
Make sure your environment’s jvm is 1.7
# verify the version
java -version# set the JAVA_HOME to the appropriate path (like this on osx)
export JAVA_HOME=/Library/Java/JavaVirtualMachines/1.7.0.jdk/Contents/HomeRun the conversion
export MAVEN_OPTS=-Dfile.encoding=UTF-8 mvn exec:java -Dexec.mainClass="jon.Convert" -Dexec.args="/path/to/exported/sites/ /path/to/markdown/destination"
So let’s try it out:
elatov@fed:/opt/work/mig$cd sites-to-markdown/
elatov@fed:/opt/work/mig/sites-to-markdown$ls
pom.xml README.md src
elatov@fed:/opt/work/mig/sites-to-markdown$java -version
java version "1.7.0_65"
OpenJDK Runtime Environment (fedora-2.5.1.3.fc20-x86_64 u65-b17)
OpenJDK 64-Bit Server VM (build 24.65-b04, mixed mode)
elatov@fed:/opt/work/mig/sites-to-markdown$export JAVA_HOME=/usr/lib/jvm/java-1.7.0/jre
elatov@fed:/opt/work/mig/sites-to-markdown$export MAVEN_OPTS=-Dfile.encoding=UTF-8
elatov@fed:/opt/work/mig/sites-to-markdown$mvn exec:java -Dexec.mainClass="jon.Convert" -Dexec.args="~/g-sites/home ~/g-sites-md"
After a lot of dependencies, it failed with the following message:
[WARNING] Warning: killAfter is now deprecated. Do you need it ? Please comment on MEXEC-6.
[WARNING]
java.lang.ClassNotFoundException: jon.Convert
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at org.codehaus.mojo.exec.ExecJavaMojo$1.run(ExecJavaMojo.java:281)
at java.lang.Thread.run(Thread.java:745)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 44.416s
[INFO] Finished at: Sat Jul 26 10:18:16 MDT 2014
[INFO] Final Memory: 14M/108M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.3.1:java (default-cli) on project ConvertWiki: An exception occured while executing the Java class. jon.Convert -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
It looks like it’s a known issue, and here is link that talks about the fix. To fix it, just run mvn install and then it works fine:
elatov@fed:/opt/work/mig/sites-to-markdown$mvn install
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building ConvertWiki 0.0.1-SNAPSHOT
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ ConvertWiki ---
Downloading: http://repo.maven.apache.org/maven2/junit/junit/3.8.1/junit-3.8.1.pom
Downloaded: http://repo.maven.apache.org/maven2/junit/junit/3.8.1/junit-3.8.1.pom (998 B at 3.8 KB/sec)
...
....
Downloaded: http://repo.maven.apache.org/maven2/org/codehaus/plexus/plexus-utils/3.0.5/plexus-utils-3.0.5.jar (226 KB at 452.8 KB/sec)
[INFO] Installing /opt/work/mig/sites-to-markdown/target/ConvertWiki-0.0.1-SNAPSHOT.jar to /home/elatov/.m2/repository/ConvertWiki/ConvertWiki/0.0.1-SNAPSHOT/ConvertWiki-0.0.1-SNAPSHOT.jar
[INFO] Installing /opt/work/mig/sites-to-markdown/pom.xml to /home/elatov/.m2/repository/ConvertWiki/ConvertWiki/0.0.1-SNAPSHOT/ConvertWiki-0.0.1-SNAPSHOT.pom
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12.639s
[INFO] Finished at: Sat Jul 26 10:21:56 MDT 2014
[INFO] Final Memory: 16M/174M
[INFO] ------------------------------------------------------------------------
And then it worked:
elatov@fed:/opt/work/mig/sites-to-markdown$mvn exec:java -Dexec.mainClass="jon.Convert" -Dexec.args="/home/elatov/g-sites/home /home/elatov/g-sites-md"
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building ConvertWiki 0.0.1-SNAPSHOT
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] --- exec-maven-plugin:1.3.1:java (default-cli) @ ConvertWiki ---
[WARNING] Warning: killAfter is now deprecated. Do you need it ? Please comment on MEXEC-6.
Unhandled element table
Unhandled element tbody
Unhandled element tr
Unhandled element td
Unhandled element td
Unhandled element tt
Unhandled element tt
Unhandled element tt
Unhandled element tt
Unhandled element tt
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 5.100s
[INFO] Finished at: Sat Jul 26 10:23:59 MDT 2014
[INFO] Final Memory: 11M/175M
[INFO] ------------------------------------------------------------------------
It looks like it couldn’t handle a table, but that should be okay. The only weird thing about the conversion was the image links, they were in the following format:
[
](home sharepoint install reg_user_edit_page png?attredirects=0)
It looks like it’s an imbedded image link within a regular URL link. In markdown, here is an image link:

And here is just a regular link:
[link-title](http://url-to-link.com)
And it was also pointing to the original image link which was in google sites. I already had the local version of the images downloaded, so let’s fix all the links to point to the local images. I wrote a quick python script to search for a regular expression and substitute the matched expession, here is the script:
elatov@fed:~/g-sites-md$cat md-img-fix.py
#!/usr/bin/env python
import re, sys
img = re.compile('\[\!\[\]\(https://sites.google.com/a/company.com/notes/_/rsrc/(.*?)/(.*?)\)\n\]\((.*?)\)',re.M)
# set the first arguement as the file we are going to modify
file = sys.argv[1]
# open the file as read only
fh = open(file,'r')
data = fh.read()
if img.findall(data):
new_data = img.sub(r'',data)
fh.close()
nf = open(file,'w')
nf.write(new_data)
nf.close()
and here is a quick example of what it changes:
elatov@fed:~/g-sites-md$python md-img-fix.py adfs-as-an-idp.md
elatov@fed:~/g-sites-md$diff adfs-as-an-idp.md adfs-as-an-idp.md.orig | head -6
23c23,24
< 
---
> [
> ](home adfs as an idp adfs_from_start_menu png?attredirects=0)
30c31,32
Another nuisance of the conversion is that it prepends everything with a dash(-), I ended using mmv to clean those up. First run the command to see what it’s going to do:
elatov@fed:~/g-sites-md$mmv -n "\-*" "#1"
-stuff-as-factor-.md -> stuff-as-factor.md
-more-factor.md -> more-factor.md
If everything looks good, then actuallly run it:
elatov@fed:~/g-sites-md$mmv "\-*" "#1"
To convert all the pages, we can just run the python script through a for loop:
elatov@fed:~/g-sites-md$for file in $(ls *.md); do echo $file; python md-img-fix.py $file; done
Convert Markdown to Word Doc Format
There is a cool tool called pandoc which can convert markdown to .docx format, from their main page:
If you need to convert files from one markup format into another, pandoc is your swiss-army knife. Pandoc can convert documents in markdown, reStructuredText, textile, HTML, DocBook, LaTeX, MediaWiki markup, OPML, Emacs Org-Mode, or Haddock markup to
- HTML formats: XHTML, HTML5, and HTML slide shows using Slidy, reveal.js, Slideous, S5, or DZSlides.
- Word processor formats: Microsoft Word docx, OpenOffice/LibreOffice ODT, OpenDocument XML
- Ebooks: EPUB version 2 or 3, FictionBook2
- Documentation formats: DocBook, GNU TexInfo, Groff man pages, Haddock markup
- Page layout formats: InDesign ICML
- Outline formats: OPML
- TeX formats: LaTeX, ConTeXt, LaTeX Beamer slides
- PDF via LaTeX
- Lightweight markup formats: Markdown, reStructuredText, AsciiDoc, MediaWiki markup, Emacs Org-Mode, Textile
- Custom formats: custom writers can be written in lua.
So let’s install the software:
elatov@fed:~$sudo yum install pandoc
Now let’s try to convert one markdown page:
pandoc -o output.docx -f markdown -t docx markdown-file.md
If you then open up the word document you will see your images in the document:
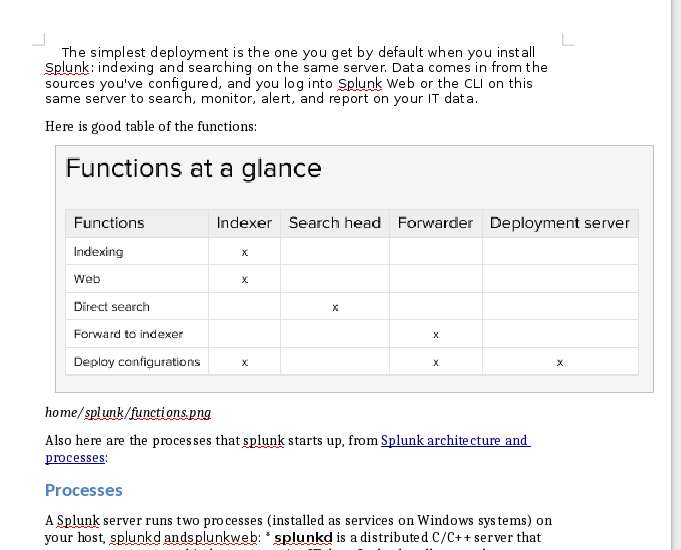
You can do the same thing and use a for loop to convert all the documents:
elatov@fed:~/g-sites-md$for file in $(ls *.md); do echo $file; pandoc -o $(basename $file .md).docx -f markdown -t docx $file; done
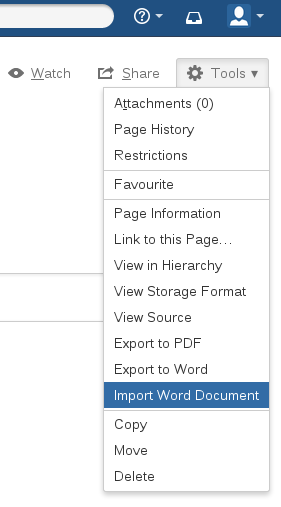
Import Word Document into Confluence
From the Tools menu you can select the Import Word Document option:
Upon initial import, I received the following error:
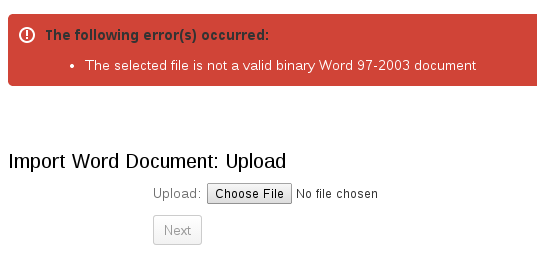
It looks like I need a .doc format and not .docx format. Abiword can convert between the two formats:
$abiword -t doc splunk.docx
Here is a for loop to convert all the docx files into doc files:
$for file in $(ls *.docx); do echo $file; abiword -t doc $file; done
Then after it recognized the .doc format, I received yet another error:

Looks like I need to go through all my images and make sure the size is below 900x1200. So let’s get a feel of how many images I will have to convert. Here is command that will count all the images that have a width above 900 pixels:
elatov@fed:~/g-sites$find . -name "*.png" -exec exiftool -s -ImageWidth {} \; | awk '$3 > 900' | wc -l
217
And for the height:
elatov@fed:~/g-sites$find . -name "*.png" -exec exiftool -s -ImageHeight {} \; | awk '$3 > 1200' | wc -l
0
Looks like I just need to concentrate on the 217 images with the large width. So I decided to write a python script to take care of the conversion. Here is the script.
elatov@fed:~/g-sites$cat resize-img.py
#!/usr/bin/env python
import glob,magic
import os,sys,re
from PIL import Image
dir = sys.argv[1]
def width_gt_nine(png_file):
dim_pat = re.compile('(\d+) x (\d+)')
magic_data = magic.from_file(png_file)
png_width = dim_pat.search(magic_data).group(1)
png_height = dim_pat.search(magic_data).group(2)
if int(png_width) > 900:
return (True, png_height)
else:
return (False, png_height)
def resize_img(png_file,png_width,png_height):
img = Image.open(png_file)
img.resize((png_width,png_height),Image.ANTIALIAS).save(png_file)
for root, dirs, files in os.walk(dir):
for file in files:
if file.endswith(".png"):
res, height = width_gt_nine(os.path.join(root, file))
if res:
resize_img(os.path.join(root, file),899,int(height))
Before running the script back up all the images just in case:
elatov@fed:~/g-sites$find . -name "*.png" -exec cp {} {}.bak \;
It has a couple of dependencies, here is what I did to install them:
elatov@fed:~$sudo pip install python-magic
elatov@fed:~$sudo yum install python-pillow
Be careful with the magic module cause there are two different ones with the same name. Check out the differences here. Then I just ran the script on the whole home (this was the root of the google sites export) directory:
elatov@fed:~/g-sites$./resize-img.py home/
The script sets the width of the image to 899 pixels, so let’s see how many files have that width set:
elatov@fed:~/g-sites$find . -name "*.png" -exec exiftool -s -ImageWidth {} \; | awk '$3 == 899' | wc -l
217
That confirms that the script changed all of the necessary files. Lastly we can check to see no images have a width over 900:
elatov@fed:~/g-sites$find . -name "*.png" -exec exiftool -s -ImageWidth {} \; | awk '$3 > 900' | wc -l
0
That looks good, now let’s re-run the conversion from markdown to .docx:
elatov@fed:~/g-sites-md$for file in $(ls *.md); do echo $file; pandoc -o $(basename $file .md).docx -f markdown -t docx $file; done
and then from .docx to .doc:
elatov@fed:~/g-sites-md$for file in $(ls *.docx); do echo $file; abiword -t doc $file; done
Now re-uploading the same document, I got an error message saying that the size of the biggest image was 1187 x 1126, so the size changed but it didn’t reflect the actual size (cause I converted them to 899 x original height).
I then modifed the script and the set the width to be 799 pixels and then Confluence told me that the biggest size is 1055 x 1084. It went down but still not enough. After I set the width to be 699 pixels all the documents went throught without any issues. Not sure if Confluence is reading the size wrong (maybe it’s not using pixels to check the size) or if the Python PIL module is not converting the images correctly. I only had 6 pages out of 50 that had that issue and going to a lower size didn’t bother me.
In summary, I would say 85% of the import went well with regards to images (This depends if you have big images in your google sites). The code blocks didn’t really convert over (so I will fix those manually), but the rest of the formating (headings, links, images, bold and italic text) was there. Here is snippet of the converted page that I had originally shown with Word: