Manually Deploy Kubernetes on CoreOS
Deploying Kubernetes 1.5.x on CoreOS
I started out with an older version of CoreOS and just kept updating it. I also had an old version of etcd (version 2) and newer versions of Kubernetes required etcd3. So at first I decided to deploy an older version of kubernetes. There are actually pretty nice instructions at these sites:
- Setup Kubernetes on CoreOS
- Deploy Kubernetes Master Node(s)
- How to Deploy Kubernetes on CoreOS Cluster
Create SSL Certificates
The easiest thing to do is use of the scripts provided in the above sites. Here is what I ended up with:
# cat gen-certs.sh
#!/bin/bash
# Creating TLS certs
echo "Creating CA ROOT**********************************************************************"
openssl genrsa -out ca-key.pem 2048
openssl req -x509 -new -nodes -key ca-key.pem -days 10000 -out ca.pem -subj "/CN=kube-ca"
echo "creating API Server certs*************************************************************"
master_Ip=192.168.1.106
cat >openssl.cnf<<EOF
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster.local
IP.1 = 10.3.0.1
IP.2 = $master_Ip
EOF
openssl genrsa -out apiserver-key.pem 2048
openssl req -new -key apiserver-key.pem -out apiserver.csr -subj "/CN=kube-apiserver" -config openssl.cnf
openssl x509 -req -in apiserver.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out apiserver.pem -days 365 -extensions v3_req -extfile openssl.cnf
echo "Creating Admin certs********************************************************"
openssl genrsa -out admin-key.pem 2048
openssl req -new -key admin-key.pem -out admin.csr -subj "/CN=kube-admin"
openssl x509 -req -in admin.csr -CA ca.pem -CAkey ca-key.pem -CAcreateserial -out admin.pem -days 365
echo "DONE !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
Then after running that script, you will have the following files:
core certs # ls
admin-key.pem admin.pem apiserver.csr ca-key.pem ca.srl openssl.cnf
admin.csr apiserver-key.pem apiserver.pem ca.pem gen-certs.sh
So let’s put the files into a location for kubernetes to use:
core certs # mkdir -p /etc/kubernetes/ssl
core certs # cp *.pem /etc/kubernetes/ssl
Configuring Flannel
Initially I wanted to use flannel for networking, so I created the following files:
core # cat /etc/kubernetes/cni/docker_opts_cni.env
DOCKER_OPT_BIP=""
DOCKER_OPT_IPMASQ=""
core # cat /etc/kubernetes/cni/net.d/10-flannel.conf
{
"name": "podnet",
"type": "flannel",
"delegate": {
"isDefaultGateway": false
}
}
core # cat /etc/systemd/system/docker.service.d/60-docker-wait-for-flannel-config.conf
[Unit]
After=flanneld.service
Requires=flanneld.service
[Service]
Restart=always
EnvironmentFile=/etc/kubernetes/cni/docker_opts_cni.env
[Install]
WantedBy=multi-user.target
core # cat /etc/systemd/system/flanneld.service.d/40-ExecStartPre-symlink.conf
[Service]
ExecStartPre=/usr/bin/ln -sf /etc/flannel/options.env /run/flannel/options.env
From my previous config with flannel, I already had a network defined:
core ~ # etcdctl get /coreos.com/network/config
{"Network":"10.2.0.0/16", "Backend": {"Type": "vxlan"}}
Create the kubelet Service
Next we can create a service that will run all the containers for kubernetes. Here is the version for 1.5.1:
core # cat /etc/systemd/system/kubelet.service
[Service]
Environment=KUBELET_VERSION=v1.5.1_coreos.0
Environment="RKT_OPTS=--uuid-file-save=/var/run/kubelet-pod.uuid \
--volume var-log,kind=host,source=/var/log \
--mount volume=var-log,target=/var/log \
--volume dns,kind=host,source=/etc/resolv.conf \
--mount volume=dns,target=/etc/resolv.conf"
ExecStartPre=/usr/bin/mkdir -p /etc/kubernetes/manifests
ExecStartPre=/usr/bin/mkdir -p /var/log/containers
ExecStartPre=-/usr/bin/rkt rm --uuid-file=/var/run/kubelet-pod.uuid
ExecStart=/usr/lib/coreos/kubelet-wrapper \
--api-servers=http://127.0.0.1:8080 \
--register-schedulable=false \
--cni-conf-dir=/etc/kubernetes/cni/net.d \
--network-plugin=cni \
--container-runtime=docker \
--allow-privileged=true \
--pod-manifest-path=/etc/kubernetes/manifests \
--hostname-override=192.168.1.106 \
--cluster_dns=10.3.0.10 \
--cluster_domain=cluster.local
ExecStop=-/usr/bin/rkt stop --uuid-file=/var/run/kubelet-pod.uuid
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Now let’s create the containers for kubernetes.
Create the API Service Pod
Here is the first one:
core # cat /etc/kubernetes/manifests/kube-apiserver.yaml
apiVersion: v1
kind: Pod
metadata:
name: kube-apiserver
namespace: kube-system
spec:
hostNetwork: true
containers:
- name: kube-apiserver
image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
command:
- /hyperkube
- apiserver
- --bind-address=0.0.0.0
- --etcd-servers=http://192.168.1.106:2379
- --allow-privileged=true
- --service-cluster-ip-range=10.3.0.0/24
- --secure-port=443
- --advertise-address=192.168.1.106
- --admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota
- --tls-cert-file=/etc/kubernetes/ssl/apiserver.pem
- --tls-private-key-file=/etc/kubernetes/ssl/apiserver-key.pem
- --client-ca-file=/etc/kubernetes/ssl/ca.pem
- --service-account-key-file=/etc/kubernetes/ssl/apiserver-key.pem
- --runtime-config=extensions/v1beta1/networkpolicies=true
- --anonymous-auth=false
livenessProbe:
httpGet:
host: 127.0.0.1
port: 8080
path: /healthz
initialDelaySeconds: 15
timeoutSeconds: 15
ports:
- containerPort: 443
hostPort: 443
name: https
- containerPort: 8080
hostPort: 8080
name: local
volumeMounts:
- mountPath: /etc/kubernetes/ssl
name: ssl-certs-kubernetes
readOnly: true
- mountPath: /etc/ssl/certs
name: ssl-certs-host
readOnly: true
volumes:
- hostPath:
path: /etc/kubernetes/ssl
name: ssl-certs-kubernetes
- hostPath:
path: /usr/share/ca-certificates
name: ssl-certs-host
Next we have the kube-proxy
Create the kube-proxy Pod
Similar thing as the API server let’s create a Pod for the kube-proxy:
core # cat /etc/kubernetes/manifests/kube-proxy.yaml
apiVersion: v1
kind: Pod
metadata:
name: kube-proxy
namespace: kube-system
spec:
hostNetwork: true
containers:
- name: kube-proxy
image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
command:
- /hyperkube
- proxy
- --master=http://127.0.0.1:8080
securityContext:
privileged: true
volumeMounts:
- mountPath: /etc/ssl/certs
name: ssl-certs-host
readOnly: true
volumes:
- hostPath:
path: /usr/share/ca-certificates
name: ssl-certs-host
Next is the kube-controller-manager.
Create the kube-controller-manager Pod
Here is the file:
core # cat /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
name: kube-controller-manager
namespace: kube-system
spec:
hostNetwork: true
containers:
- name: kube-controller-manager
image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
command:
- /hyperkube
- controller-manager
- --master=http://127.0.0.1:8080
- --leader-elect=true
- --service-account-private-key-file=/etc/kubernetes/ssl/apiserver-key.pem
- --root-ca-file=/etc/kubernetes/ssl/ca.pem
resources:
requests:
cpu: 200m
livenessProbe:
httpGet:
host: 127.0.0.1
path: /healthz
port: 10252
initialDelaySeconds: 15
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/kubernetes/ssl
name: ssl-certs-kubernetes
readOnly: true
- mountPath: /etc/ssl/certs
name: ssl-certs-host
readOnly: true
hostNetwork: true
volumes:
- hostPath:
path: /etc/kubernetes/ssl
name: ssl-certs-kubernetes
- hostPath:
path: /usr/share/ca-certificates
name: ssl-certs-host
And lastly we have the kube-scheduler.
Create the kube-scheduler Pod
Here is the file for that:
core # cat /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
name: kube-scheduler
namespace: kube-system
spec:
hostNetwork: true
containers:
- name: kube-scheduler
image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
command:
- /hyperkube
- scheduler
- --master=http://127.0.0.1:8080
- --leader-elect=true
resources:
requests:
cpu: 100m
livenessProbe:
httpGet:
host: 127.0.0.1
path: /healthz
port: 10251
initialDelaySeconds: 15
timeoutSeconds: 15
Starting up all services
Now we just need to apply the configs and start up all the pods. First reload all the services:
core # systemctl daemon-reload
core # systemctl restart flanneld
core # systemctl restart docker
And then lastly start the kubelet service:
core # systemd start kubelet
You should see something like this for the status:
core ~ # systemctl status kubelet -f
● kubelet.service
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2017-11-11 09:48:35 MST; 3s ago
Process: 29019 ExecStop=/usr/bin/rkt stop --uuid-file=/var/run/kubelet-pod.uuid (code=exited, status=0/SUCCESS)
Process: 29041 ExecStartPre=/usr/bin/rkt rm --uuid-file=/var/run/kubelet-pod.uuid (code=exited, status=0/SUCCESS)
Process: 29038 ExecStartPre=/usr/bin/mkdir -p /var/log/containers (code=exited, status=0/SUCCESS)
Process: 29035 ExecStartPre=/usr/bin/mkdir -p /etc/kubernetes/manifests (code=exited, status=0/SUCCESS)
Main PID: 29076 (kubelet)
Tasks: 24 (limit: 32768)
Memory: 65.8M
CPU: 2.020s
CGroup: /system.slice/kubelet.service
├─29076 /kubelet --api-servers=http://127.0.0.1:8080 --register-schedulable=false --network-plugin=cni --container-runtime=docker --allow-privileged=true --pod-manifest-path=/etc/kubernetes/manifests --hostname-override=192.168.1
└─29126 journalctl -k -f
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.457532 29076 factory.go:54] Registering systemd factory
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.457990 29076 factory.go:86] Registering Raw factory
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.458352 29076 manager.go:1106] Started watching for new ooms in manager
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.460015 29076 oomparser.go:185] oomparser using systemd
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.460860 29076 manager.go:288] Starting recovery of all containers
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.543873 29076 kubelet_node_status.go:204] Setting node annotation to enable volume controller attach/detach
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.553148 29076 kubelet_node_status.go:74] Attempting to register node 192.168.1.106
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.565394 29076 kubelet_node_status.go:113] Node 192.168.1.106 was previously registered
Nov 11 09:48:36 core kubelet-wrapper[29076]: I1111 16:48:36.565416 29076 kubelet_node_status.go:77] Successfully registered node 192.168.1.106
You can also make sure you can query the API service:
core ~ # curl http://127.0.0.1:8080/version
{
"major": "1",
"minor": "5",
"gitVersion": "v1.5.1+coreos.0",
"gitCommit": "cc65f5321f9230bf9a3fa171155c1213d6e3480e",
"gitTreeState": "clean",
"buildDate": "2016-12-14T04:08:28Z",
"goVersion": "go1.7.4",
"compiler": "gc",
"platform": "linux/amd64"
}
Install kubectl
The last thing we can do is install kubectl so we can manage the kubenetes cluster. Download the binary:
core ~ # cd /opt/bin/
core bin # curl -O https://storage.googleapis.com/kubernetes-release/release/v1.5.1/bin/linux/amd64/kubectl
core bin # chmod +x kubectl
Then configure kubectl:
core ~ # kubectl config set-cluster default-cluster --server=https://192.168.1.106 --certificate-authority=/etc/kubernetes/ssl/ca.pem
Cluster "default-cluster" set.
core ~ # kubectl config set-credentials default-admin --certificate-authority=/etc/kubernetes/ssl/ca.pem --client-key=/etc/kubernetes/ssl/admin-key.pem --client-certificate=/etc/kubernetes/ssl/admin.pem
User "default-admin" set.
core ~ # kubectl config set-context default-system --cluster=default-cluster --user=default-admin
Context "default-system" set.
core ~ # kubectl config use-context default-system
Switched to context "default-system".
And now make the master available for new deployments:
core # kubectl get no
NAME STATUS AGE
192.168.1.106 Ready,SchedulingDisabled 1h
core # kubectl uncordon 192.168.1.106
node "192.168.1.106" uncordoned
core # kubectl get no
NAME STATUS AGE
192.168.1.106 Ready 1h%
At this point you can do a quick deploy and confirm the pod is up:
core ~ # wget https://k8s.io/docs/tasks/run-application/deployment.yaml
core ~ # kubectl apply -f deployment.yaml
core ~ # kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-deployment-431080787-g6z6c 1/1 Running 0 5m
nginx-deployment-431080787-ggq6t 1/1 Running 0 5m
So the basics are working.
Updating Kubernetes 1.5.1 to 1.6.1
At this point I wanted to deploy the kubernetes dashboard and I ran into an issue:
core ~ # kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
secret "kubernetes-dashboard-certs" created
serviceaccount "kubernetes-dashboard" created
Error from server (BadRequest): error when creating "https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml": Role in version "v1beta1" cannot be handled as a Role: no kind "Role" is registered for version "rbac.authorization.k8s.io/v1beta1"
Error from server (BadRequest): error when creating
It looks like the latest dashboard depends on RBAC functionality which was introduced in Kubernetes 1.6. I ran into a good site (Upgrading Kubernetes on a Baremetal CoreOS Cluster From Version 1.5 to 1.6) which actually talks about updating kubernetes to 1.6.1 and it actually involves updating etcd2 to etcd3. So first let’s do that, I just followed the steps laid out in the web page.
Stop Kubernetes 1.5.1
Let’s drain our master node:
core ~ # kubectl drain 192.168.1.106 --force
node "192.168.1.106" already cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: kube-apiserver-192.168.1.106, kube-controller-manager-192.168.1.106, kube-proxy-192.168.1.106, kube-scheduler-192.168.1.106
node "192.168.1.106" drained
core ~ # kubectl get nodes
NAME STATUS AGE
192.168.1.106 Ready,SchedulingDisabled 1h
Next let’s stop the kubelet service:
core ~ # systemctl stop kubelet
Now let’s stop all the containers:
core ~ # docker ps -a | grep kube | awk '{print $1}' | xargs docker stop
core ~ # docker ps -a | grep kube | awk '{print $1}' | xargs docker rm
Now we are ready to update etcd.
Update etcd2 to etcd3
Make sure the cluster is currently healthy:
core ~ # etcdctl cluster-health
member ce2a822cea30bfca is healthy: got healthy result from http://192.168.1.106:2379
cluster is healthy
Now let’s stop the service and disable it from starting up:
core ~ # systemctl stop etcd2
core ~ # systemctl disable etcd2
Now let’s make a backup of the etcd2 data:
core ~ # etcdctl backup --data-dir /var/lib/etcd2 --backup-dir /home/core/etcd2-backup
Now let’s copy the old data into the new data directory:
core ~ # rm -rf /var/lib/etcd/*
core ~ # cp -a /var/lib/etcd2/* /var/lib/etcd
Next let’s create a new service which will start etcd3. I ended up doing the following:
core ~ # mkdir /etc/systemd/system/etcd-member.service.d
core ~ # cp /run/systemd/system/etcd2.service.d/20-cloudinit.conf /etc/systemd/system/etcd-member.service.d/.
core ~ # cp /etc/systemd/system/etcd2.service.d/50-network-config.conf /etc/systemd/system/etcd-member.service.d/.
Now let’s start the new service:
core ~ # systemctl daemon-reload
core ~ # systemctl enable etcd-member
Created symlink /etc/systemd/system/multi-user.target.wants/etcd-member.service → /usr/lib/systemd/system/etcd-member.service.
core ~ # systemctl start etcd-member
And you can confirm the service started up successfully:
core ~ # systemctl status etcd-member
● etcd-member.service - etcd (System Application Container)
Loaded: loaded (/usr/lib/systemd/system/etcd-member.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/etcd-member.service.d
└─20-cloudinit.conf, 50-network-config.conf
Active: active (running) since Sat 2017-11-11 11:10:42 MST; 1s ago
Docs: https://github.com/coreos/etcd
Process: 26514 ExecStartPre=/usr/bin/rkt rm --uuid-file=/var/lib/coreos/etcd-member-wrapper.uuid (code=exited, status=254)
Process: 26510 ExecStartPre=/usr/bin/mkdir --parents /var/lib/coreos (code=exited, status=0/SUCCESS)
Main PID: 26522 (etcd)
Tasks: 13 (limit: 32768)
Memory: 111.1M
CPU: 2.362s
CGroup: /system.slice/etcd-member.service
└─26522 /usr/local/bin/etcd
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.420693 I | raft: raft.node: ce2a822cea30bfca elected leader ce2a822cea30bfca at term 20
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.420925 I | etcdserver: updating the cluster version from 2.3 to 3.1
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427604 N | etcdserver/membership: updated the cluster version from 2.3 to 3.1
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427635 I | etcdserver/api: enabled capabilities for version 3.1
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427661 I | embed: ready to serve client requests
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427831 I | etcdserver: published {Name:core ClientURLs:[http://192.168.1.106:2379]} to cluster 7e27652122e8b2ae
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427862 I | embed: ready to serve client requests
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.427967 N | embed: serving insecure client requests on [::]:2379, this is strongly discouraged!
Nov 11 11:10:42 core etcd-wrapper[26522]: 2017-11-11 18:10:42.428207 N | embed: serving insecure client requests on [::]:4001, this is strongly discouraged!
Nov 11 11:10:42 core systemd[1]: Started etcd (System Application Container).
And make sure the cluster is still healthy:
core ~ # etcdctl cluster-health
member ce2a822cea30bfca is healthy: got healthy result from http://192.168.1.106:2379
cluster is healthy
The last step is to migrate the data, first let’s download a new binary:
core ~ # cd /opt/
core opt # wget https://github.com/coreos/etcd/releases/download/v3.2.0/etcd-v3.2.0-linux-amd64.tar.gz
core opt # tar xzf etcd-v3.2.0-linux-amd64.tar.gz
core opt # cd etcd-v3.2.0-linux-amd64
core etcd-v3.2.0-linux-amd64 # ETCDCTL_API=3 ./etcdctl migrate --data-dir=/var/lib/etcd
using default transformer
2017-11-11 11:12:36.123567 I | etcdserver/api: enabled capabilities for version 2.3
2017-11-11 11:12:36.123606 I | etcdserver/membership: added member ce2a822cea30bfca [http://localhost:2380 http://localhost:7001] to cluster 0 from store
2017-11-11 11:12:36.123614 I | etcdserver/membership: set the cluster version to 2.3 from store
2017-11-11 11:12:36.129480 N | etcdserver/membership: updated the cluster version from 2.3 to 3.1
2017-11-11 11:12:36.129514 I | etcdserver/api: enabled capabilities for version 3.1
waiting for etcd to close and release its lock on "/var/lib/etcd/member/snap/db"
finished transforming keys
Next let’s update kubernetes manifest files to use the new version.
Update Kubernetes Pods
If you look at the config now, it will look like this:
core ~ # grep v1.5.1_coreos.0 /etc/systemd/system/kubelet.service
Environment=KUBELET_VERSION=v1.5.1_coreos.0
core ~ # grep -R v1.5.1_coreos.0 /etc/kubernetes/manifests/*
/etc/kubernetes/manifests/kube-apiserver.yaml: image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
/etc/kubernetes/manifests/kube-controller-manager.yaml: image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
/etc/kubernetes/manifests/kube-proxy.yaml: image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
/etc/kubernetes/manifests/kube-scheduler.yaml: image: quay.io/coreos/hyperkube:v1.5.1_coreos.0
So first update the kubelet service:
core ~ # grep v1.6.1_coreos.0 /etc/systemd/system/kubelet.service
Environment=KUBELET_IMAGE_TAG=v1.6.1_coreos.0
And the update the manifest files:
core ~ # sed -i 's/v1.5.1_coreos.0/v1.6.1_coreos.0/' /etc/kubernetes/manifests/*
And now the versions will look like this:
core ~ # grep -R v1.6.1_coreos.0 /etc/kubernetes/manifests/*
/etc/kubernetes/manifests/kube-apiserver.yaml: image: quay.io/coreos/hyperkube:v1.6.1_coreos.0
/etc/kubernetes/manifests/kube-controller-manager.yaml: image: quay.io/coreos/hyperkube:v1.6.1_coreos.0
/etc/kubernetes/manifests/kube-proxy.yaml: image: quay.io/coreos/hyperkube:v1.6.1_coreos.0
/etc/kubernetes/manifests/kube-scheduler.yaml: image: quay.io/coreos/hyperkube:v1.6.1_coreos.0
Now let’s start up the new Pods:
core ~ # systemctl daemon-reload
core ~ # systemctl start kubelet
You should see the API service respond with the following:
core ~ # curl http://127.0.0.1:8080/version
{
"major": "1",
"minor": "6",
"gitVersion": "v1.6.1+coreos.0",
"gitCommit": "9212f77ed8c169a0afa02e58dce87913c6387b3e",
"gitTreeState": "clean",
"buildDate": "2017-04-04T00:32:53Z",
"goVersion": "go1.7.5",
"compiler": "gc",
"platform": "linux/amd64"
}
Lastly just re-enable the master node to be part of the cluster:
core ~ # kubectl uncordon 192.168.1.106
Update Kubernetes 1.6.1 to 1.7.2
At this point when I tried to deploy the dashboard I recieved different errors but still related to permission issues:
core # wget https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
core # kubectl apply -f kubernetes-dashboard.yaml
secret "kubernetes-dashboard-certs" configured
serviceaccount "kubernetes-dashboard" configured
deployment "kubernetes-dashboard" created
service "kubernetes-dashboard" created
unable to decode "kubernetes-dashboard.yaml": no kind "Role" is registered for version "rbac.authorization.k8s.io/v1beta1"
unable to decode "kubernetes-dashboard.yaml": no kind "RoleBinding" is registered for version "rbac.authorization.k8s.io/v1beta1"
So I deleted the deployment:
core # kubectl delete -f kubernetes-dashboard.yaml
secret "kubernetes-dashboard-certs" deleted
serviceaccount "kubernetes-dashboard" deleted
rolebinding "kubernetes-dashboard-minimal" deleted
deployment "kubernetes-dashboard" deleted
service "kubernetes-dashboard" deleted
Error from server (NotFound): error when deleting "kubernetes-dashboard.yaml": roles.rbac.authorization.k8s.io "kubernetes-dashboard-minimal" not found
And updated to 1.7.2 since that’s what the file recommended:
Configuration to deploy release version of the Dashboard UI compatible with Kubernetes 1.7.
I followed a similar approach as before. Delete/Stop everything and update the manifest files to use the new version and restart the Pods. In the end I had the following:
core # sed -i 's/v1.6.1_coreos.0/v1.7.2_coreos.0/' /etc/kubernetes/manifests/*
core # grep v1.7 /etc/kubernetes/manifests/*
/etc/kubernetes/manifests/kube-apiserver.yaml: image: quay.io/coreos/hyperkube:v1.7.2_coreos.0
/etc/kubernetes/manifests/kube-controller-manager.yaml: image: quay.io/coreos/hyperkube:v1.7.2_coreos.0
/etc/kubernetes/manifests/kube-proxy.yaml: image: quay.io/coreos/hyperkube:v1.7.2_coreos.0
/etc/kubernetes/manifests/kube-scheduler.yaml: image: quay.io/coreos/hyperkube:v1.7.2_coreos.0
core ~ # systemctl daemon-reload
core ~ # systemctl start kubelet
I also updated the kubectl binary:
core ~ # cd /opt/bin/
core bin # mv kubectl kubectl.1.5.1
core bin # curl -O https://storage.googleapis.com/kubernetes-release/release/v1.7.2/bin/linux/amd64/kubectl
core bin # chmod +x kubectl
And here is the final result:
core ~ # kubectl get no
NAME STATUS AGE VERSION
192.168.1.106 Ready 2h v1.7.2+coreos.0
I tried deploying the dashboard and recieved another permission error:
core dashboard # kubectl create -f kubernetes-dashboard.yaml
secret "kubernetes-dashboard-certs" created
serviceaccount "kubernetes-dashboard" created
rolebinding "kubernetes-dashboard-minimal" created
deployment "kubernetes-dashboard" created
service "kubernetes-dashboard" created
Error from server (Forbidden): error when creating "kubernetes-dashboard.yaml": roles.rbac.authorization.k8s.io "kubernetes-dashboard-minimal" is forbidden: attempt to grant extra privileges: [PolicyRule{Resources:["secrets"], APIGroups:[""], Verbs:["create"]} PolicyRule{Resources:["secrets"], APIGroups:[""], Verbs:["watch"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-key-holder"], APIGroups:[""], Verbs:["get"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-certs"], APIGroups:[""], Verbs:["get"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-key-holder"], APIGroups:[""], Verbs:["update"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-certs"], APIGroups:[""], Verbs:["update"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-key-holder"], APIGroups:[""], Verbs:["delete"]} PolicyRule{Resources:["secrets"], ResourceNames:["kubernetes-dashboard-certs"], APIGroups:[""], Verbs:["delete"]} PolicyRule{Resources:["services"], ResourceNames:["heapster"], APIGroups:[""], Verbs:["proxy"]}] user=&{kube-admin [system:authenticated] map[]} ownerrules=[PolicyRule{Resources:["selfsubjectaccessreviews"], APIGroups:["authorization.k8s.io"], Verbs:["create"]} PolicyRule{NonResourceURLs:["/version" "/api" "/api/*" "/apis" "/apis/*"], Verbs:["get"]} PolicyRule{NonResourceURLs:["/healthz"], Verbs:["get"]} PolicyRule{NonResourceURLs:["/swaggerapi"], Verbs:["get"]} PolicyRule{NonResourceURLs:["/swaggerapi/*"], Verbs:["get"]}] ruleResolutionErrors=[]
Kubernetes kubelet Parameter Changes
I then ran into:
- Fresh Dedicated Server To Single Node Kubernetes Cluster On CoreOS, Part 2: Getting Kubernetes Running
- Fresh Dedicated Server To Single Node Kubernetes Cluster On CoreOS, Part 3: Setting Up Essential Kubernetes Addons
There were changes in some of the parameters. I added:
--register-node=true \
--require-kubeconfig \
--kubeconfig=/etc/kubernetes/kubeconfig.yaml
To /etc/systemd/system/kubelet.service and then after restarting the service, I added kube-admin to the cluster admin role (as per the instructions in the following pages):
Here is the command for that:
core dashboard # kubectl create clusterrolebinding a-cluster-admin-binding --clusterrole=cluster-admin --user=kube-admin
Then the dashboard deployed successfully:
core dashboard # kubectl create -f kubernetes-dashboard.yaml
secret "kubernetes-dashboard-certs" created
serviceaccount "kubernetes-dashboard" created
role "kubernetes-dashboard-minimal" created
rolebinding "kubernetes-dashboard-minimal" created
deployment "kubernetes-dashboard" created
service "kubernetes-dashboard" created
And I saw all the components deployed:
core # rkt list
UUID APP IMAGE NAME STATE CREATED STARTED NETWORKS
084fe4b8 hyperkube quay.io/coreos/hyperkube:v1.7.2_coreos.0 running 2 minutes ago 2 minutes ago
2a13bab4 flannel quay.io/coreos/flannel:v0.8.0 running 8 hours ago 8 hours ago
d67a53c9 etcd quay.io/coreos/etcd:v3.1.10 running 8 hours ago 8 hours ago
And also kubernetes pods:
core # kubectl get all --all-namespaces=true
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system po/kube-apiserver-192.168.1.106 1/1 Running 0 6m
kube-system po/kube-controller-manager-192.168.1.106 1/1 Running 0 6m
kube-system po/kube-proxy-192.168.1.106 1/1 Running 0 6m
kube-system po/kube-scheduler-192.168.1.106 1/1 Running 0 6m
NAMESPACE NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default svc/kubernetes 10.3.0.1 <none> 443/TCP 12h
Flannel and docker Interface Conflict
Whenever I would try to expose the kubernetes dashboard service (as per the instructions in Accessing Dashboard 1.7.X and above), I would see the following in the logs:
Nov 11 12:04:15 core kubelet-wrapper[6871]: W1111 19:04:15.759201 6871 docker_sandbox.go:342] failed to read pod IP from plugin/docker: NetworkPlugin cni failed on the status hook for pod "kubernetes-dashboard-150844358-bsmgf_kube-system": CNI failed to retrieve network namespace path: Cannot find network namespace for the terminated container "b01749c91e4583201a0c64680e83f332efe5cdc4db37ed28b8b30682538ca83d"
And I noticed that bother the docker0 and cni0 interfaces would have the same IP:
core ~ # ip -4 a s dev docker0
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
inet 10.2.67.1/24 scope global docker0
valid_lft forever preferred_lft forever
core ~ # ip -4 a s dev cni0
22: cni0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1450 qdisc htb state UP group default qlen 1000
inet 10.2.67.1/24 scope global cbr0
valid_lft forever preferred_lft forever
There were a bunch of people running into the issue:
- Couldn’t find network status for {namespace}/{pod_name} through plugin: invalid network status for
- cni plugin + flannel on v1.3: pods can’t route to service IPs
- kubernetes cni plugin + flannel + docker networking issues
Some folks recommended removing the –bip parameter from docker, but I already had that removed:
core ~ # ps -ef | grep dockerd
root 1199 1 0 Nov12 ? 00:14:01 /run/torcx/bin/dockerd --host=fd:// --containerd=/var/run/docker/libcontainerd/docker-containerd.sock --selinux-enabled=true --insecure-registry=0.0.0.0/0 --mtu=1450
And I actually had other containers that I deployed with docker-compose and I didn’t want to impact them. Since I was using a single machine for my testing, I decided to use the kubenet network plugin instead of cni. To do that I modified the /etc/systemd/system/kubelet.service to have this:
--network-plugin=kubenet \
--pod-cidr=10.2.68.0/24 \
Instead of this:
--cni-conf-dir=/etc/kubernetes/cni/net.d \
--network-plugin=cni \
I will have to check out if I can use flannel for both some time later. But after that I was able to expose the service without issues:
core ~ # kubectl get all --all-namespaces=true
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system po/kube-apiserver-192.168.1.106 1/1 Running 6 2d
kube-system po/kube-controller-manager-192.168.1.106 1/1 Running 9 2d
kube-system po/kube-proxy-192.168.1.106 1/1 Running 8 2d
kube-system po/kube-scheduler-192.168.1.106 1/1 Running 9 2d
kube-system po/kubernetes-dashboard-1592587111-2lk87 1/1 Running 0 2d
NAMESPACE NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default svc/kubernetes 10.3.0.1 <none> 443/TCP 3d
kube-system svc/kubernetes-dashboard 10.3.0.175 <nodes> 443:30443/TCP 2d
NAMESPACE NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kube-system deploy/kubernetes-dashboard 1 1 1 1 2d
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system rs/kubernetes-dashboard-1592587111 1 1 1 2d
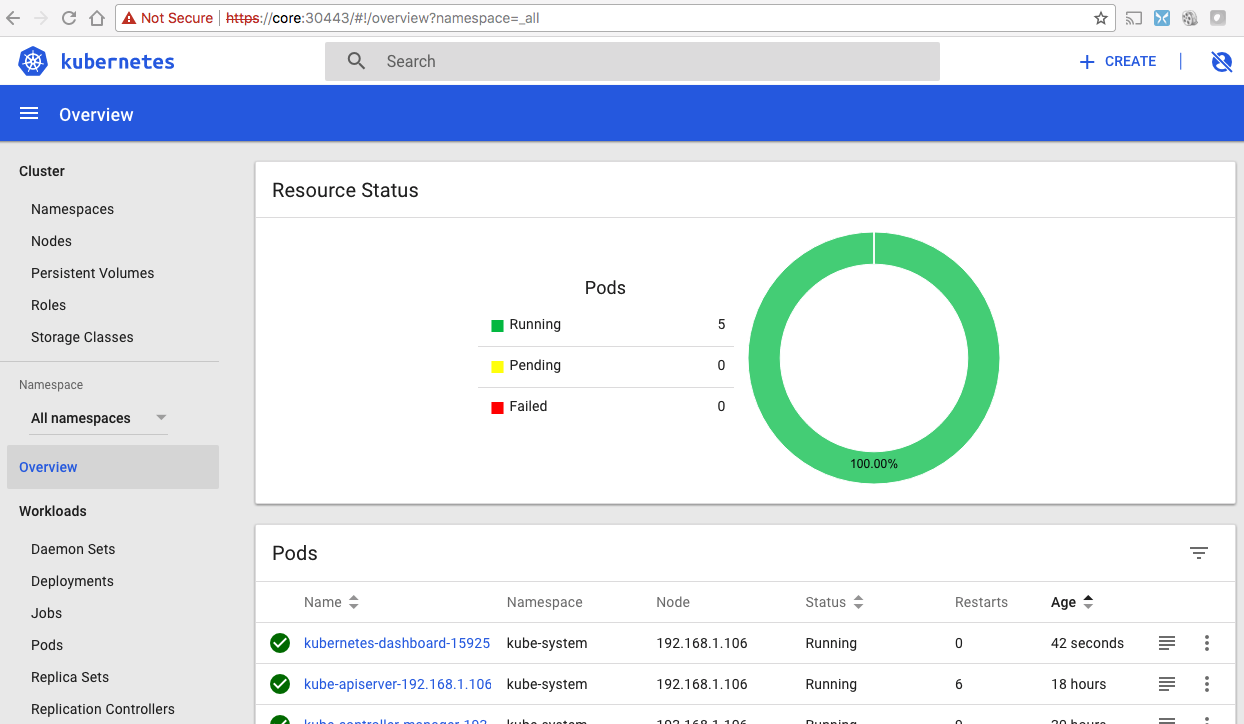
And I was able to get into the dashboard to check out my kubernetes resources: