Distributed Systems Design - Netflix
Let’s try to cover some of the components of the Netflix Architecture. As with the twitter post I ran into a bunch of resources on this topic:
And here are some nice YouTube Videos:
- NETFLIX System design, software architecture for netflix
- Netflix System Design, Media Streaming Platform
- Netflix System Design, YouTube System Design
And here are some nice diagrams I ran into:
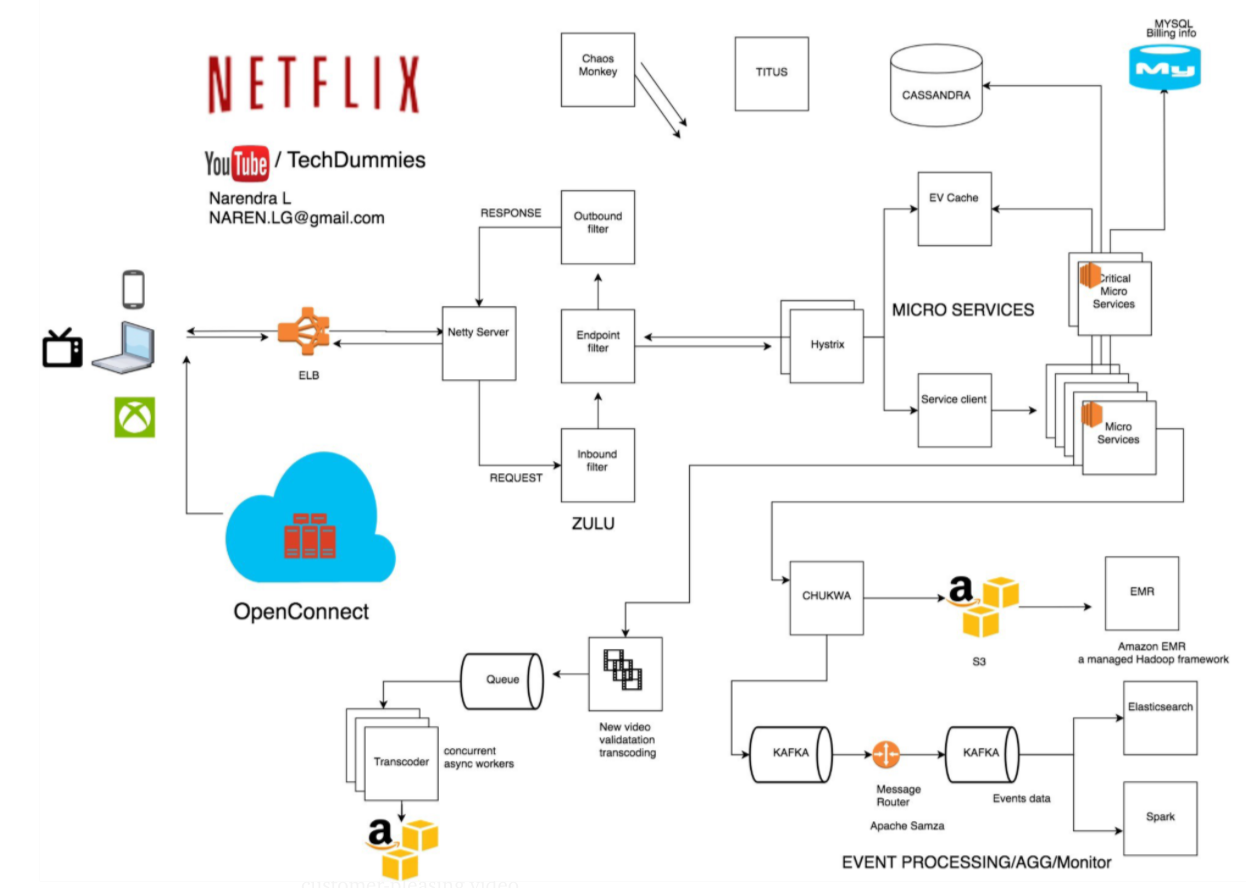
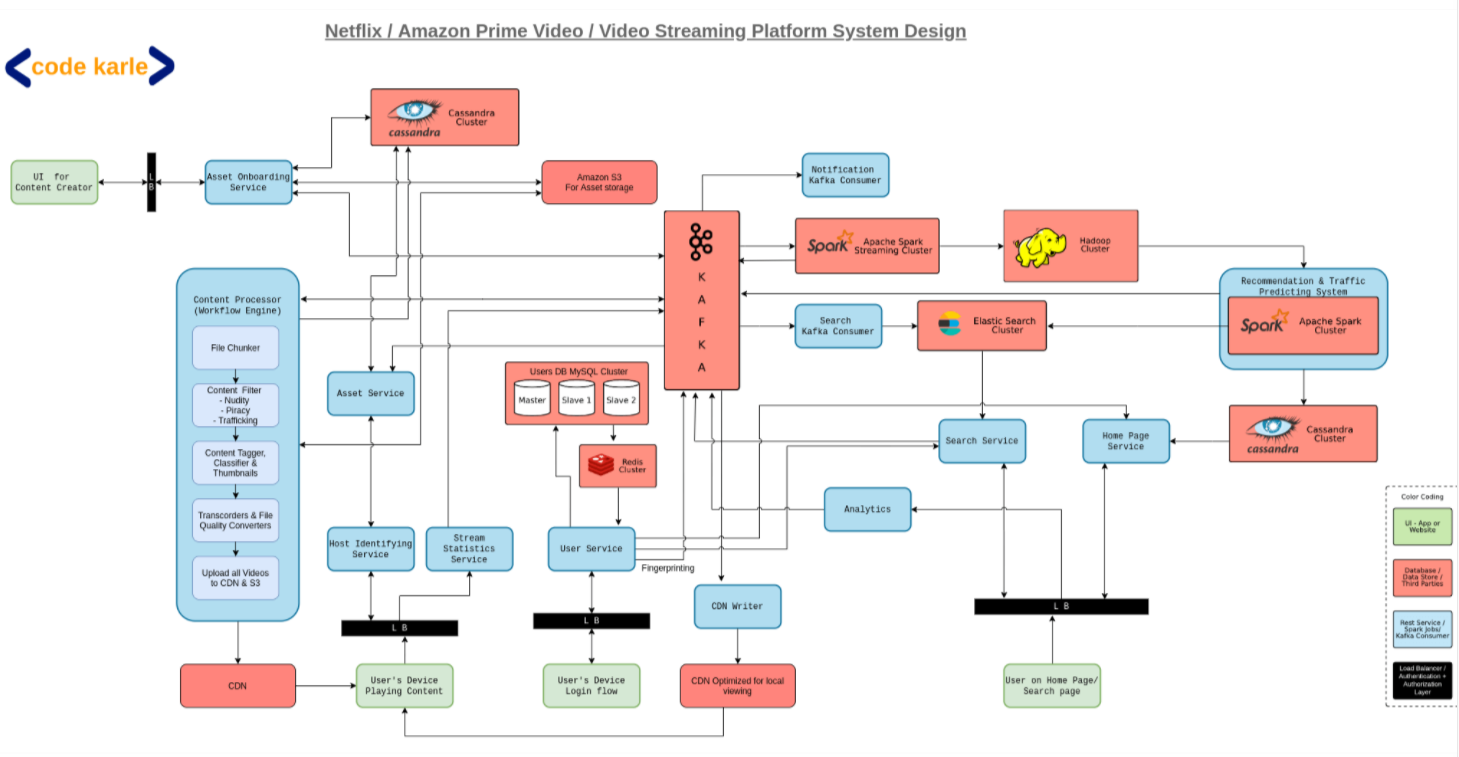
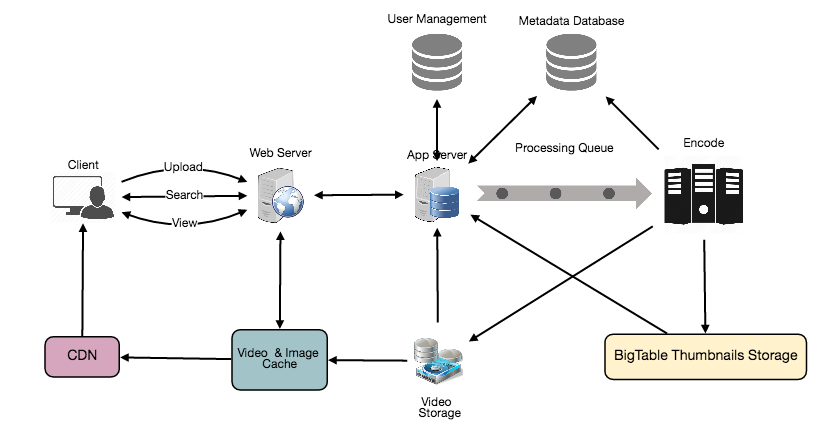
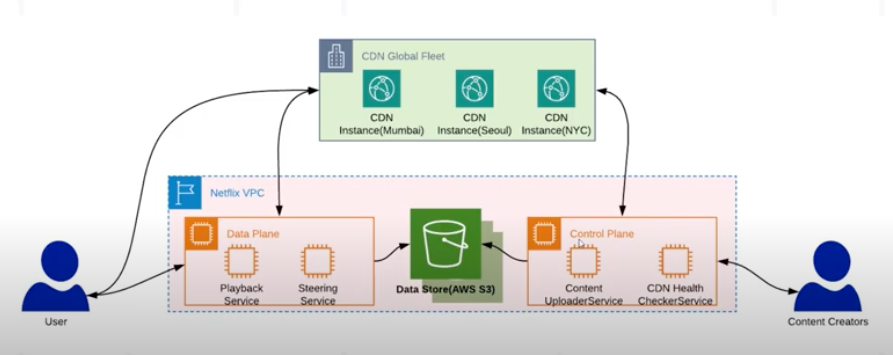
I am going to break down into parts that stuck out to me.
Uploading a Video
When a user uploads a video a lot happens in the back ground. Some things that were interesting to me is that the video is first broken apart into many chunks and then each chunk is transcoded or encoded into multiple different formats. This way it’s preparing the contents to be played by multiple different players and also different resolutions based on the bandwidth.
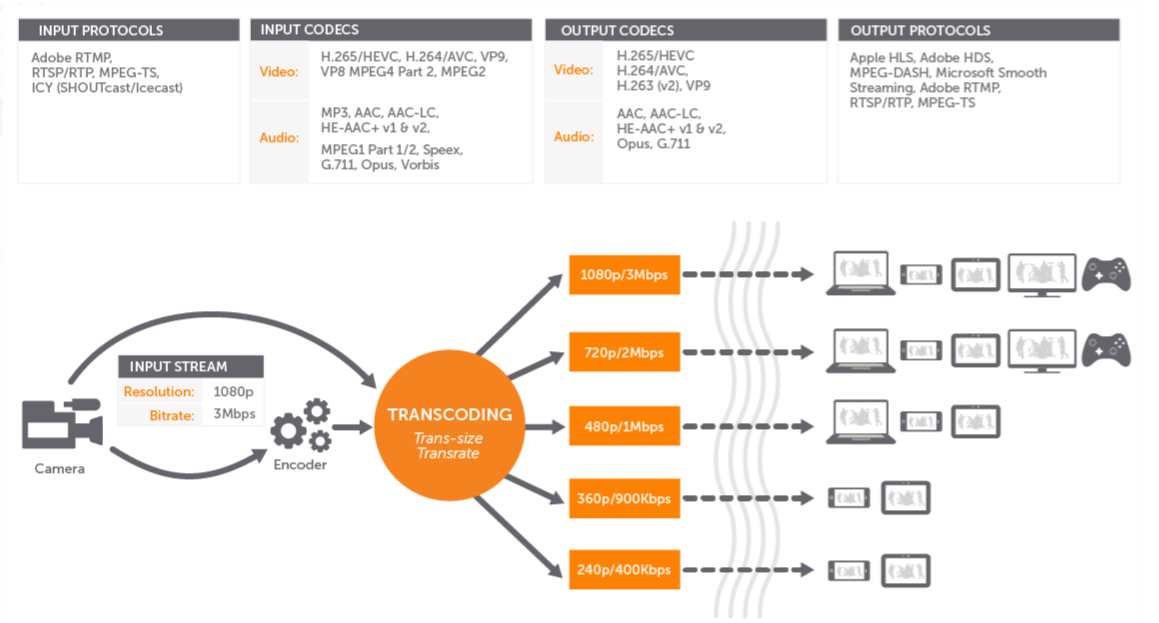
At the same time other processes are kicked off to update the analytics pipeline and the search databases. At the end the chunk is written to cache which is closest to the user, but more on that later.
Spark and Elasticsearch
Spark and ElasticSearch are used for analytics and search capabilities. Spark is focused on processing data in parallel across a cluster of multiple compute nodes. A lot of the times Spark is compared with Hadoop… one of the differences between them is Hadoop reads and writes files to HDFS, while Spark processes data in RAM using a concept known as an RDD, Resilient Distributed Dataset. Both products are used for processing lots of data in a distributed manner and that output of the data can provide analytics.
Elasticsearch is a search engine which is based on Apache Lucene. Elasticsearch is a NoSQL database which means it stores data in an unstructured way and while you can’t run complex queries on it like with a typical RDBMS, you can shard the data across multiple nodes a lot easier. There are many different NoSQL databases out there, however unlike most , Elasticsearch has a strong focus on search capabilities.
Kafka
Since there are a couple of processes happening at the same time how do they all get started? Whenever you are streaming new data and want to communicate across multiple products/processes a queue comes to mind. Kafka is a distributed streaming platform that is used publish and subscribe to streams of records. Kafka replicates topic log partitions to multiple servers. Kafka is used for real-time streams of data, to collect big data, or to do real time analysis (or both). While Kafka is great choice for distributing your message queue it also comes with a caveat and that is ordering. As with any messaging queue there is a producer and a subscriber, and they use a topic to communicate. When the topic is partitioned into multiple parts (or sharded) to allow for scalability we can run into a scenario where messages are placed into different partitions and we don’t know in which order the producer sent them to each partition. There are actually a couple of pretty cool posts on this: A Visual Understanding to Ensuring Your Kafka Data is (Literally) in Order and Does Kafka really guarantee the order of messages?
Whenever you have a microservice architecture (where each service is responsible for a small action) a message queue comes it handy to coordinate between all the services. Since netflix uses a lot of miroservices to scale the processing of the data, kafka plays a major role to ensuring a successful result is the outcome.
CDN (Content Delivery Network)
After the media file is chunked and transcoded into many pieces it is placed into an amazon blob storage (AWS S3).
AWS S3
A BLOB storage is a binary large object data store. A lot of cloud providers provide one: AWS S3, GCP Cloud Storage, and Azure Blob Storage. They offer performance and scalability of cloud with advanced security and sharing capabilities. You are able to store large files which are automatically sharded across multiple regions and provide durability. Since AWS S3 provided their service across multiple regions it was a natural fit for netflix.
OCA (Open Connect Appliance)
While there are multiple CDNs (Fastly, Akamai, and cloudflare) Netflix decided to create it’s own appliance to cache the media files from the S3 Buckets. And they placed their appliances at the ISPs datacenters so they can be closer to the users:
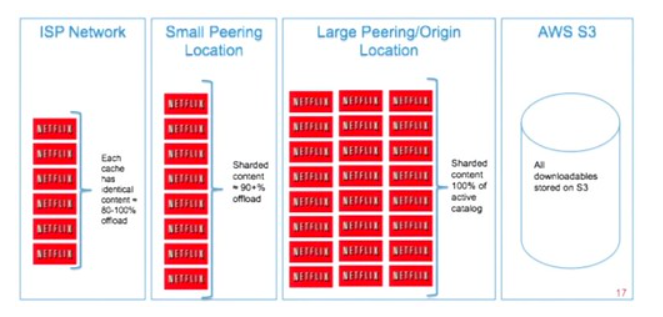
CDN Caching Capabilities
A content delivery network (CDN) is a globally distributed network of servers, serving content from locations closer to the user across multiple geolocations. Generally, static files such as HTML/CSS/JS, photos, and videos are served from CDN. The are a couple of concepts here, like a Cache Hit (which is when you get the data you wanted from the cache) and there is also a Cache Miss (which is when the data you request is not in the cache and the cache system has to go to the backend to retrieve the data and store it in the cache). Usually the first request ends up in a Cache Miss. You can also set a TTL when the data is expired from the cache so you can provide space for other data to be cached.
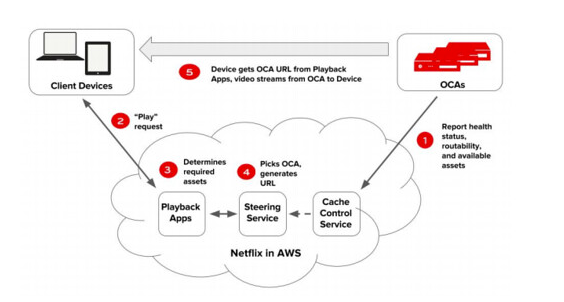
Client playing a video
Now that we have all the components created all we have to do is forward the client to the appropriate cache location closest to the client. This is handled my another microservice called the steering service it figures out which location is the best and then forwards the user there: