Distributed Systems Design - Uber
You know the drill here are some existing materials.
Existing Material
- System Design of Uber App – Uber System Architecture
- Uber System Design Demysified
- How Uber Scales Their Real-Time Market Platform
- Designing Uber Backend
- UBER system design
- S2 Geometry Library
Here are some awesome YouTube videos:
- UBER System design, OLA system design, uber architecture
- System Design: Uber Lyft ride sharing services
- Google Maps Algorithm: Designing a location based database
And here are some sample architecture diagrams:
Geo Spatial Databases
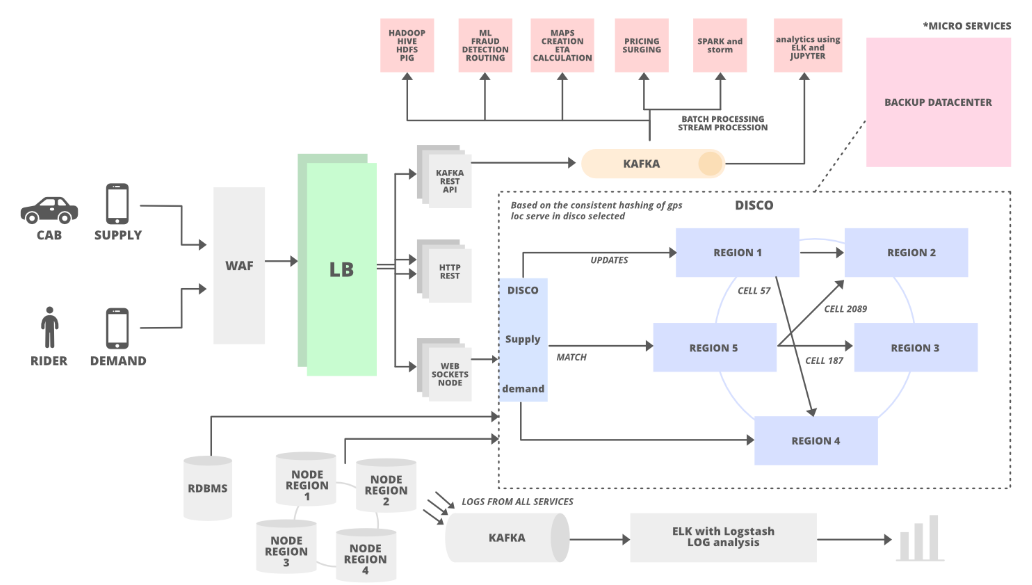
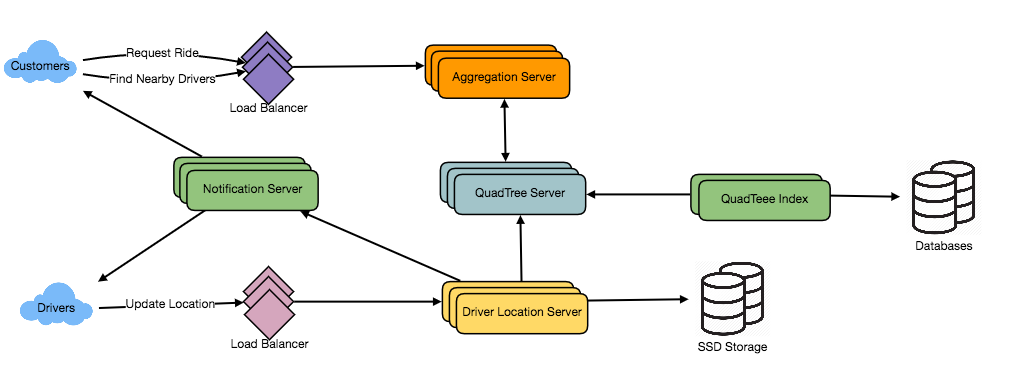
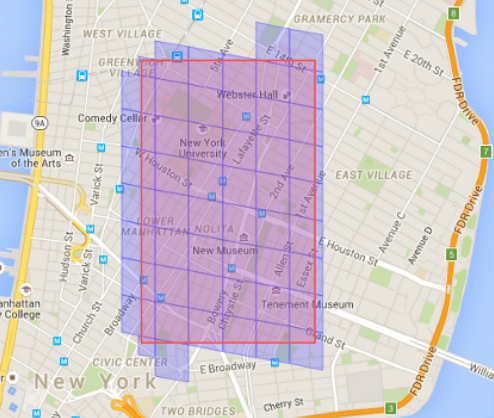
Uber uses Google S2 library (which uses a quadtree data structure). This library divides the map data into tiny cells (for example 2km) and gives the unique ID to each cell. This is a fairly easy way to spread data in a distributed system and store it easily. Suppose you want to figure out all the cabs available within a 2km radius of a city. Using the S2 libraries you can draw a circle of 2km radius and it will filter out all the cells with IDs lies in that particular circle. This way you can easily match the rider to the driver and you can easily find out the number of cab available in a particular region.
Consistent Hashing and DISCO
Uber has a Dispatch system (Dispatch optimization/DISCO) in its architecture to match cabs with users. We have discussed that the S2 library divides the map into tiny cells with a unique ID. This ID is used as a sharding key in DISCO. When cab receives the request from a user the location gets updated using the cell ID as a shard key. These tiny cells’ responsibilities will be divided into different servers lies in multiple regions (consistent hashing). From System Design of Uber App – Uber System Architecture:
For example, we can allocate the responsibility of 12 tiny cells to 6 different servers (2 cells for each server) lies in 6 different regions.
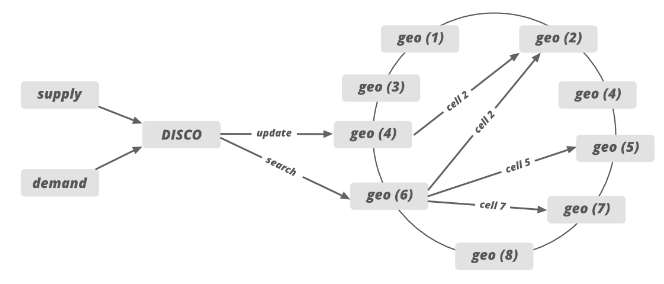
As we discussed in the past this enables easy removal and additiona of new servers.
These servers are in architecture called Ring Pop and they are equally distributed with loads when new servers are added or servers are taken down. Ringpop is a library that brings cooperation and coordination to distributed applications. It maintains a consistent hash ring on top of a membership protocol and provides request forwarding as a routing convenience. It can be used to shard your application in a way that’s scalable and fault tolerant. Gossip is a protocol used in peer-to-peer networks to enable efficient sharing of data across it’s members.
Here is a pretty good summary from Uber System Design Demysified:
The rider makes a request via websocket and this is landed to the demand service. This request will contain the type of cab and service requests.
Demand Service now passes this to the Supply service type of cab and nature of drive requested and using Google S2 library passes the cell id of the rider.
Supply service based on hashing the cell index, finds the server that will have the data related to cabs in this range of cell index. (ie) If user makes request from cell index 5, it finds the server which holds the data for this cell index and makes the call. If there are multiple indexes obtained, supply service talks to one server which functions as master and makes calls to respective all other servers and manages the communication between the servers in the ring via RPC calls.
The server now draws a circle to find all the cells from where cabs can be figured out. Then based on cabs found, it uses Map Service to find ETA and responds to Supply Service.
The supply service now sends the request back to the drivers and depending on notification / acknowledgement from driver, allocate the same to the rider.
Other Components
Here are some other components of the system worth mentioning:
- Web Sockets - is the asynchronous and event-based framework that allows you to send and receive messages through Web Sockets bi-directionally. Nowadays using gRCP with HTTP/2 is becoming a common replacement. From Data Streaming via GRPC vs MQTT vs Websockets
HTTP/1.1 HTTP/1.1(Web Sockets) HTTP/2 gRPC Request Response Model Bi-Directional Data Flow Bi-Directional Data Flow Handshake for every request Persistent connection Persistent connection Textual Protocol Textual Protocol Binary Protocol No Support for data streaming Pub/Sub based data streaming Point to Point data streaming Data format can be JSON, MQTT Data format can be JSON, MQTT Data format is protobuf Tools and libraries are abundant Limited number of tools and libraries only Google gRPC
- Kafka - The distributed messaging queue is used to send the request across multiple parts of the system: to the database for persistent storage, to spark for analytics, to ELK (ElasticSearch, LogStash, and Kibana) for logging, search, and visualizations
- Databases - Uber uses schema-less (built in-house on top of MySQL), Riak, and Cassandra. Schema-less is for long-term data storage. Riak and Cassandra meet high-availability, low-latency demands (using their own consistent hashing to spread the load.
- Redis - the in-memory database is used for both caching and queuing