Using cStor from OpenEBS
Prereqs
Most of the instructions are from cStor User Guide - install and setup. First, on all my nodes I installed the iscsi tools:
sudo apt update
sudo apt install open-iscsi
sudo systemctl enable --now iscsid
Installing and configuring OpenEBS
Then I install the operator:
kubectl apply -f https://openebs.github.io/charts/cstor-operator.yaml
After sometime you should see the pods deployed:
> k get pods -n openebs
NAME READY STATUS RESTARTS AGE
cspc-operator-64c67c894c-wld8h 1/1 Running 0 111m
cvc-operator-5697fb984f-vqtqr 1/1 Running 0 111m
openebs-cstor-admission-server-78898d4d6-bc4kn 1/1 Running 0 111m
openebs-cstor-csi-controller-0 6/6 Running 0 111m
openebs-cstor-csi-node-fw27r 2/2 Running 0 111m
openebs-cstor-csi-node-pjmw7 2/2 Running 0 111m
openebs-cstor-csi-node-sfgbv 2/2 Running 2 (86m ago) 111m
openebs-ndm-bdfqh 1/1 Running 0 111m
openebs-ndm-cluster-exporter-b5f8f4745-64r2c 1/1 Running 0 111m
openebs-ndm-node-exporter-4pz4b 1/1 Running 0 111m
openebs-ndm-node-exporter-7pfzt 1/1 Running 0 111m
openebs-ndm-node-exporter-8w5kk 1/1 Running 1 (86m ago) 111m
openebs-ndm-operator-7769f77f8b-pjdlt 1/1 Running 0 111m
openebs-ndm-s5c4n 1/1 Running 0 111m
openebs-ndm-xcbtq 1/1 Running 0 70m
And checking out the block devices I did see mine:
> kubectl get bd -n openebs
NAME NODENAME SIZE CLAIMSTATE STATUS AGE
blockdevice-029310430ed3a3c5d9f99f3b66f2cf57 na 236222135808 Unclaimed Active 71m
Checking out the logs of the disk manager, I saw the following:
> k logs -n openebs $(k get pods -n openebs -l openebs.io/component-name=ndm --field-selector spec.nodeName=na -o name)
I1221 01:03:48.427471 9 addhandler.go:105] checking if device: /dev/sda1 can be uniquely identified
I1221 01:03:48.427476 9 uuid.go:72] device(/dev/sda1) is a partition, using partition UUID: 461f6b49-d051-4d50-972e-2f3a35773a25
I1221 01:03:48.427495 9 uuid.go:91] generated uuid: blockdevice-029310430ed3a3c5d9f99f3b66f2cf57 for device: /dev/sda1
I1221 01:03:48.427504 9 addhandler.go:129] uuid: blockdevice-029310430ed3a3c5d9f99f3b66f2cf57 has been generated for device: /dev/sda1
I1221 01:03:48.427508 9 addhandler.go:46] device: /dev/sda1 already exists in cache, the event was likely generated by a partition table re-read or a change in some of the devices was detected
I1221 01:03:48.430469 9 blockdevicestore.go:145] Got blockdevice object : blockdevice-029310430ed3a3c5d9f99f3b66f2cf57
I1221 01:03:48.430488 9 addhandler.go:234] creating resource for device: /dev/sda1 with uuid: blockdevice-029310430ed3a3c5d9f99f3b66f2cf57
I1221 01:03:48.434787 9 blockdevicestore.go:112] eventcode=ndm.blockdevice.update.success msg=Updated blockdevice object rname=blockdevice-029310430ed3a3c5d9f99f3b66f2cf57
Initially I was getting the following error during the pool creation:
> k apply -f cspc.yaml
Error from server (BadRequest): error when creating "cspc.yaml": admission webhook "admission-webhook.cstor.openebs.io" denied the request: invalid cspc specification: invalid pool spec: block device has file system {ext4}
I used to have an old LVM volume on that disk, and it looks like it was able to detect it, so I cleaned it up with the following commands:
> sudo lvchange -an /dev/vg01/lv001
> sudo lvremove /dev/vg01/lv001
> sudo vgchange -an vg01
> sudo vgremove vg01
> sudo pvremove /dev/sda
I also wiped the disk as well:
> sudo wipefs -af /dev/sda
> sudo shred -vzn 1 /dev/sda
Then I restarted the pod and new device was created and the pool creation was successful:
> k delete pod -n openebs $(k get pods -n openebs -l openebs.io/component-name=ndm --field-selector spec.nodeName=na -o name)
> k get cspc -n openebs
NAME HEALTHYINSTANCES PROVISIONEDINSTANCES DESIREDINSTANCES AGE
cstor-disk-pool 1 1 1 81m
You can also make sure the instance is up and healthy:
> k get cspi -n openebs
NAME HOSTNAME FREE CAPACITY READONLY PROVISIONEDREPLICAS HEALTHYREPLICAS STATUS AGE
cstor-disk-pool-hjf2 na 211G 211010800k false 1 1 ONLINE 82m
At this point some more pods will be created, which take care of the filesystem:
> k get pod -n openebs -l openebs.io/cstor-pool-cluster=cstor-disk-pool
NAME READY STATUS RESTARTS AGE
cstor-disk-pool-hjf2-58fc768884-nmmfv 3/3 Running 0 85m
Using the cStor Disk Pool
Then after creating a PVC, you will see a new zvol created inside cstor-disk-pool pod:
> k logs -n openebs $(k get pod -n openebs -l openebs.io/cstor-pool-cluster=cstor-disk-pool -o name) -c cstor-pool
Disabling dumping core
sleeping for 2 sec
2021-12-21/01:10:31.043 disabled auto import (reading of zpool.cache)
physmem = 2038185 pages (7.78 GB)
2021-12-21/01:15:46.883 zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 status change: DEGRADED -> DEGRADED
2021-12-21/01:15:46.883 zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 rebuild status change: INIT -> INIT
2021-12-21/01:15:46.883 Instantiating zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9bd32c9c-0d50-4606-a76e-4bfab76a8c3f
...
2021-12-21/01:29:39.012 [tgt 10.96.174.21:6060:11]: Connected
2021-12-21/01:29:39.013 [tgt 10.96.174.21:6060:11]: Handshake command for zvol pvc-9e6ab37a-5148-42fa-9395-22098bcb2722
2021-12-21/01:29:39.013 Volume:cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 has zvol_guid:2765751481259197402
2021-12-21/01:29:39.013 IO sequence number:0 Degraded IO sequence number:0
2021-12-21/01:29:39.013 New data connection on fd 18
2021-12-21/01:29:39.014 ERROR fail on unavailable snapshot pvc-9e6ab37a-5148-42fa-9395-22098bcb2722@rebuild_snap
2021-12-21/01:29:39.014 Quorum is on, and rep factor 1
2021-12-21/01:29:39.014 zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 rebuild status change: INIT -> DONE
2021-12-21/01:29:39.014 zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 status change: DEGRADED -> HEALTHY
2021-12-21/01:29:39.014 Started ack sender for zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 fd: 18
2021-12-21/01:29:39.014 Data connection associated with zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 fd: 18
2021-12-21/01:29:40.023 [tgt 10.96.174.21:6060:11]: Replica status command for zvol pvc-9e6ab37a-5148-42fa-9395-22098bcb2722
2021-12-21/01:31:04.814 Waiting for refcount (2) to go down to zero on zvol:cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9bd32c9c-0d50-4606-a76e-4bfab76a8c3f
2021-12-21/01:31:04.814 Data connection for zvol cstor-f19b9fc2-5fb5-4fd8-886b-097195b45e67/pvc-9bd32c9c-0d50-4606-a76e-4bfab76a8c3f closed on fd: 17
After you deploy a pod or deployment to use the PVC it will then create a pvc target pod (which will run the iscsi target for the disk):
> k get pods -n openebs -l openebs.io/target=cstor-target
NAME READY STATUS RESTARTS AGE
pvc-9e6ab37a-5148-42fa-9395-22098bcb2722-target-6d4d866b7bbs5cx 3/3 Running 1 (71m ago) 71m
You will also see a volume created:
> k get cv -n openebs
NAME CAPACITY STATUS AGE
pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 1Gi Healthy 85m
and a replica as well:
> k get cvr -n openebs
NAME ALLOCATED USED STATUS AGE
pvc-9e6ab37a-5148-42fa-9395-22098bcb2722-cstor-disk-pool-hjf2 11.4M 33.0M Healthy 85m
And checking out the logs of the iSCSI target/PVC pod you can see the connection made from the host:
> k logs -n openebs $(k get pods -n openebs -l openebs.io/target=cstor-target -o name) -c cstor-istgt
* Starting enhanced syslogd rsyslogd
...done.
Disabling dumping core
2021-12-21/01:29:29.876 main :3117: m#-177915968.7 : istgt:0.5.20121028:14:37:28:Sep 17 2021: starting
..
..
2021-12-21/01:35:33.677 worker :5946: c#3.139805111351040.: con:3/25 [6b01a8c0:14612->10.96.174.21:3260,1]
2021-12-21/01:35:33.684 istgt_iscsi_op_log:2382: c#3.139805111351040.: Login from iqn.1993-08.org.debian:01:4efdaa48c143 (192.168.1.107) on iqn.2016-09.com.openebs.cstor:pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 LU1 (10.96.174.21:3260,1), ISID=23d000003, TSIH=2, CID=0, HeaderDigest=off, DataDigest=off
2021-12-21/01:35:33.862 istgt_lu_disk_scsi:2521: mt#1.139805136484096: c#3 Vendor specific INQUIRY VPD page 0xc9
2021-12-21/01:35:34.103 istgt_remove_conn :7130: c#2.139805086185216.: remove_conn->initiator:192.168.1.107(iqn.1993-08.org.debian:01:4efdaa48c143) Target: 10.244.50.236(iqn.2016-09.com.openebs.cstor:pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 LU1) conn:0x7f26f382f000:0 tsih:1 connections:0 IOPending=0
2021-12-21/01:35:38.675 istgt_remove_conn :7130: c#1.139805102958336.: remove_conn->initiator:192.168.1.107(iqn.1993-08.org.debian:01:4efdaa48c143) Target: 10.244.50.236(dummy LU0) conn:0x7f26f382b000:0 tsih:2 connections:0 IOPending=0
If you go directly on the node you will see the connection:
> sudo iscsiadm --mode node
10.96.174.21:3260,1 iqn.2016-09.com.openebs.cstor:pvc-9e6ab37a-5148-42fa-9395-22098bcb2722
You will also notice it’s connecting to the internal service, checking out the services I did see the one that is exposing our target pod:
> k get svc -n openebs -l openebs.io/cas-type=cstor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
pvc-9e6ab37a-5148-42fa-9395-22098bcb2722 ClusterIP 10.96.174.21 <none> 3260/TCP,7777/TCP,6060/TCP,9500/TCP 76m
Pretty nifty, also on the node you will see the disk presented at the OS level and mounted to the pod:
> sudo fdisk -l /dev/sdc
Disk /dev/sdc: 1 GiB, 1073741824 bytes, 2097152 sectors
Disk model: iscsi
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 32768 bytes / 1048576 bytes
> sudo lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 1G 0 disk /var/lib/kubelet/pods/cdb5f2f5-559e-4d53-98ef-777897259986/volumes/kubernetes.io~csi/pvc
Architecture Diagram from OpenEBS
Btw there is a nice picture of how it all works together from cStor Overview:
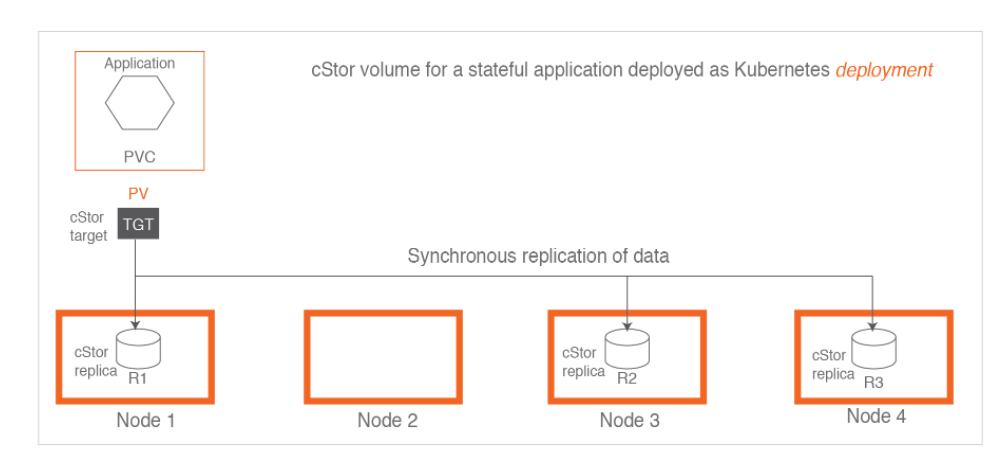
and here is an overview of how all the parts work together:
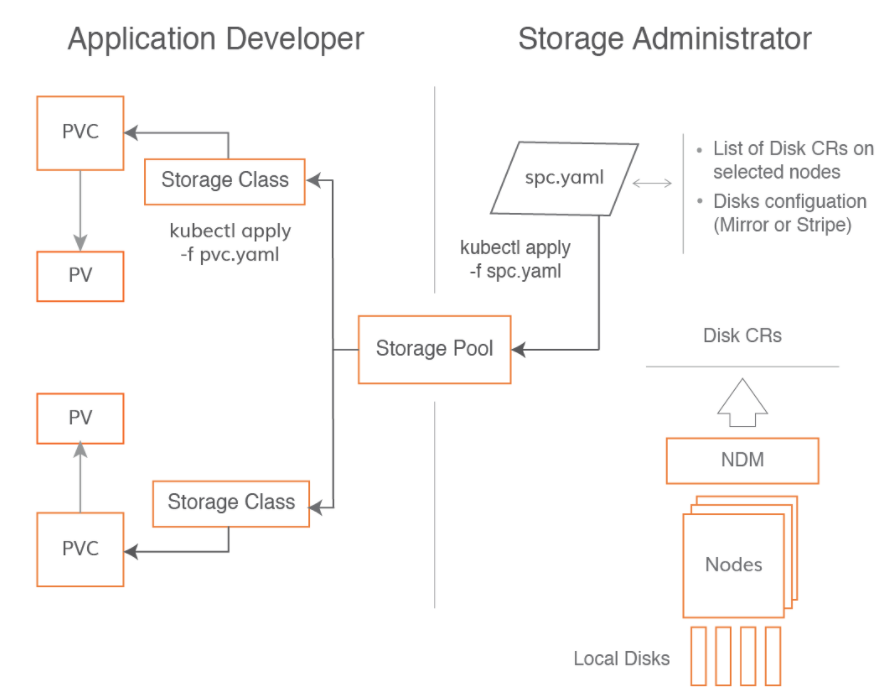
Now if I have a container that writes a bunch to an sqlite database I won’t use the NFS provider and have terrible performance: